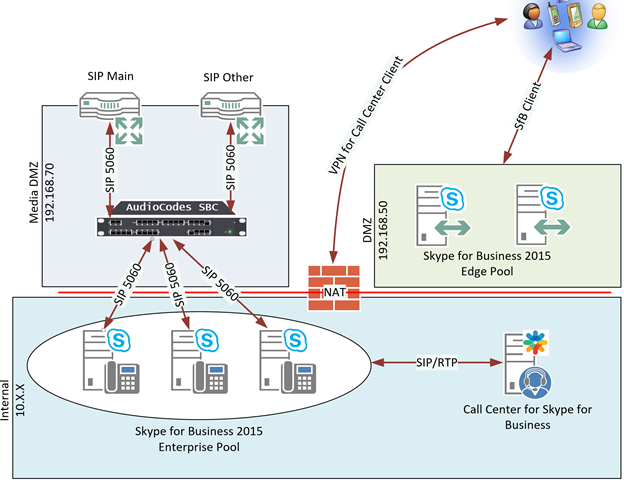
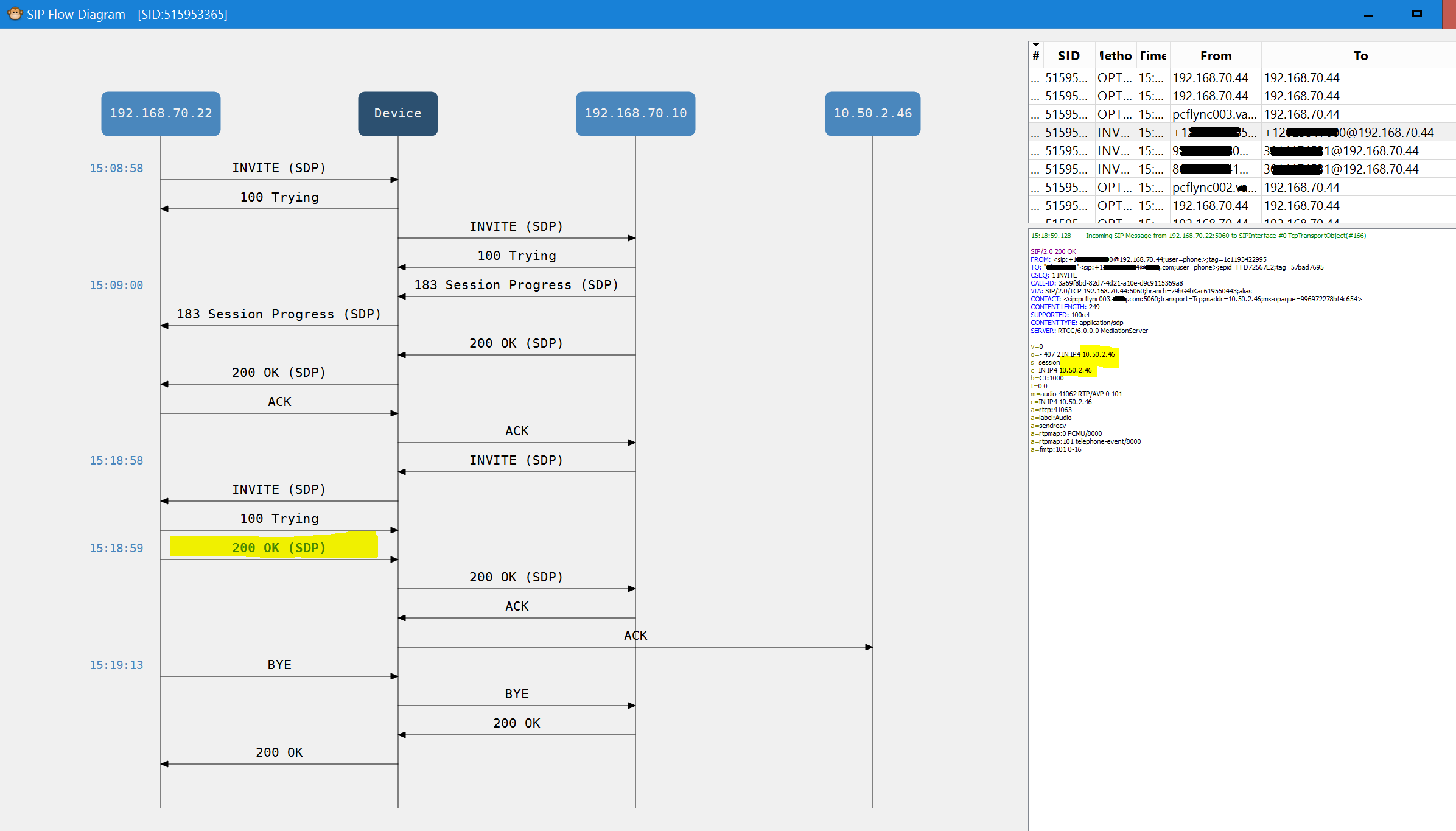
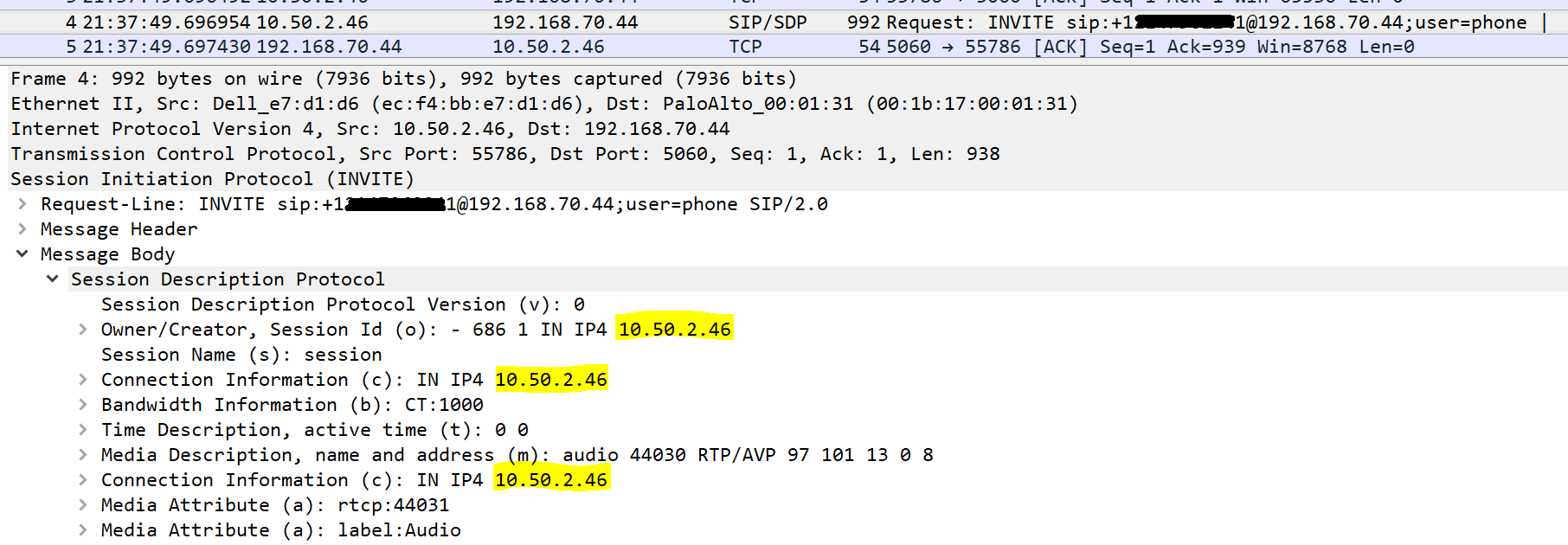
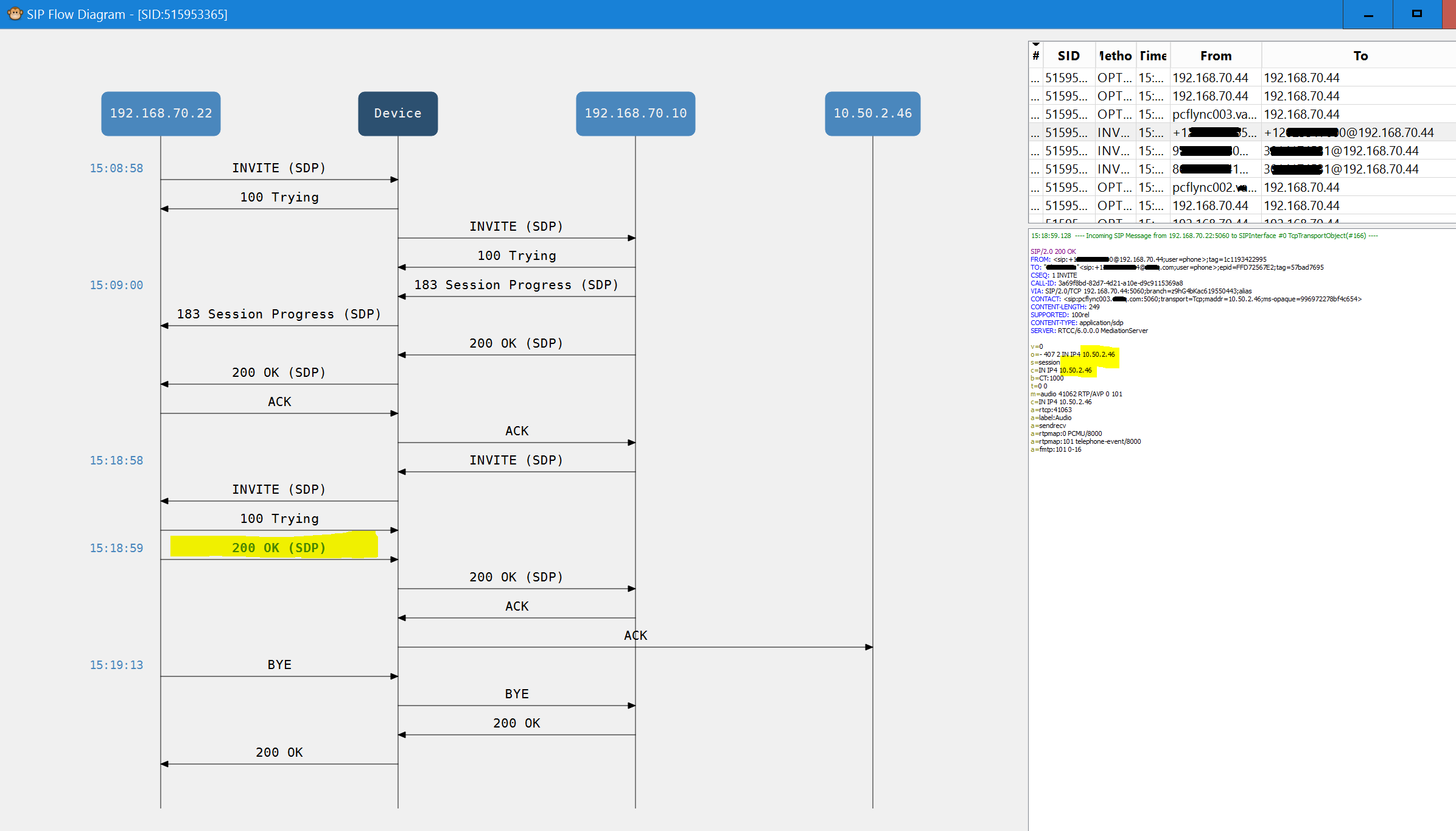
Analog trunks and devices are less and less of a factor in many of the projects that I work on. Areas where I still see analog are branch office trunks, faxes, door buzzers/enterphones, paging systems, and ring-down phones that you might see in a parking lot to contact security or a cab company.
To integrate analog trunks or devices with SfB or Teams, you connect them to a gateway. The gateway can come with two types of ports: FXO, and FXS. FXO is an abbreviation for Foreign eXchange Office, and FXS for Foreign eXchange Subscriber.
So, clear as mud and we’re done here, right? If you’re an old school telecom guy, you know there’s a lot of complexity hidden behind that simple jack in the wall. The good news is for nearly all SfB use cases we can boil things down so they’re very simple.
FXO is a port that you plug a telco trunk line into. FXS is a port that you plug your phone or other device into. Mostly. Confusion pops into the picture when you have paging systems or enterphones, which may oddly use the opposite interface than you’re expecting, or give you the option for both.
You can think of FXO and FXS as North and South on a magnet, or male and female, or whatever pairing you’d like. A FXO device plugs into an FXS device, and all is well, like this:
Your phone, which has an FXO jack on it, plugs into the wall, which is an FXS interface.
Your phone, which has an FXO jack on it, plugs into an Analog Gateway such as the AudioCodes MP-118 gateway FXS port, or an FXO/FXS card in a Sangoma for instance.
The AudioCodes MP-114 gateway FXO jack plugs into the wall, which is an FXS interface.

Great, so why then would a paging system offer both FXO and FXS interfaces? The answer is that there are two different use cases for the paging system.
One use case is a standalone, where a phone plugs directly into the paging system. You pick up the phone, maybe enter some digits to indicate what zone to page, and you talk away. The paging system is acting as a PBX in this scenario.
The second use case is PBX integrated, where the paging system acts as a phone. You dial the extension for the paging system, it rings and then answers, you maybe enter some digits to indicate what zone to page, and you talk away.
These two use cases also apply to things like enterphones or gate/door buzzers. You can have a phone plugged directly into the enterphone, or you have have the enterphone act as an extension on your PBX.
The standalone option is simple, but restricts you to interacting via a single phone. The PBX integrated option is more complex, but allows you to interact via any phone on the PBX.
Caution: “Interact via any phone on the PBX” in the SfB world means that in a global deployment, you could have a prankster user in New York telling jokes over a paging system in Paris. Configure your dial plans appropriately if your paging system doesn’t offer PIN functionality
If you have a choice between using an FXO port or FXS port on a gateway to integrate with an analog device that offers both, I recommend you pick the FXO port. This has the device act as a PBX, which means that there is no ringing when you call it, and call setup is faster. Disconnects are usually quicker too, which is important if the paging system or enterphone is used a lot.
When you configure the device to plug into an FXO port on the gateway, set the gateway to route calls to that number out via the FXO port you’ve connected it to. If the device will be sending calls to the gateway, set the gateway to
You’ll need to use an FXS port on your device to connect to the gateway’s FXO port. If your device has one port that’s switchable between FXO and FXS, read the manual carefully – I’ve seen some that aren’t clear whether they mean FXO mode is “setting this device to FXO” or “setting this device to talk to FXO”. If it’s really unclear, plug a boring analog phone in. If the line is dead, the device is set to act as an FXS device and the port is configured as an FXO interface.