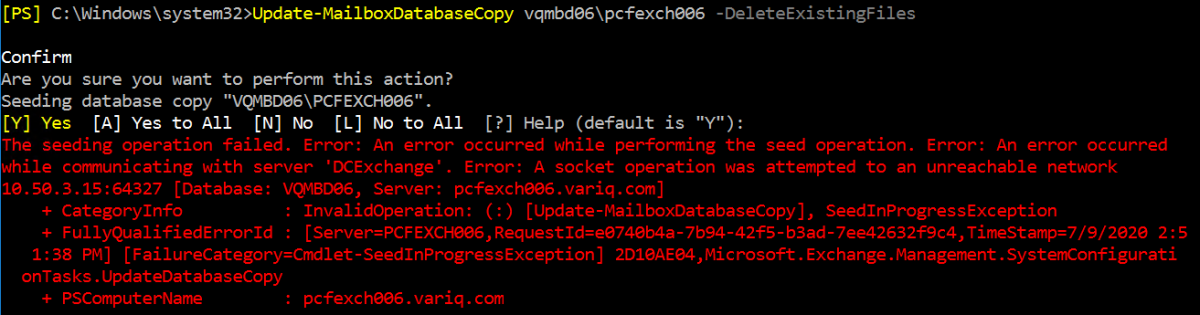
I recently came across a scenario, where an Exchange environment that had been configured in a Best Practice state had failed over to the DR site due to an extended network outage at the primary production site, and was unable to re-seed back and fail back over.
The environment was configured very similar as described in the Deploy HA documentation by Microsoft, and had it’s DAG configured across two sites:
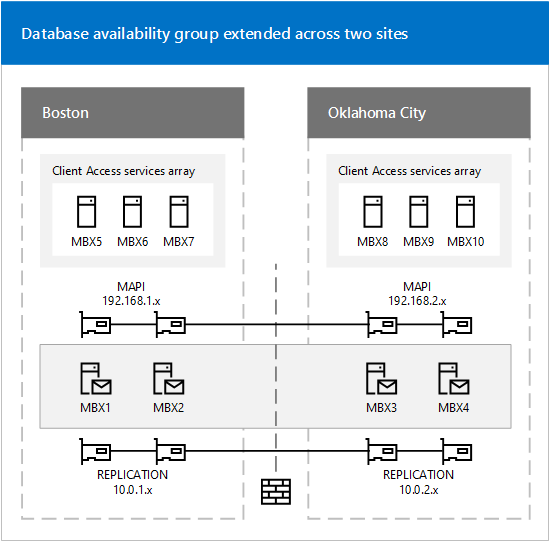
Instead of the “Replication” network that is shown in the above graphic, the primary site had a secondary network (subnet 192.168.100.x) where DPM backup services ran on, the DR site did not include a secondary network.
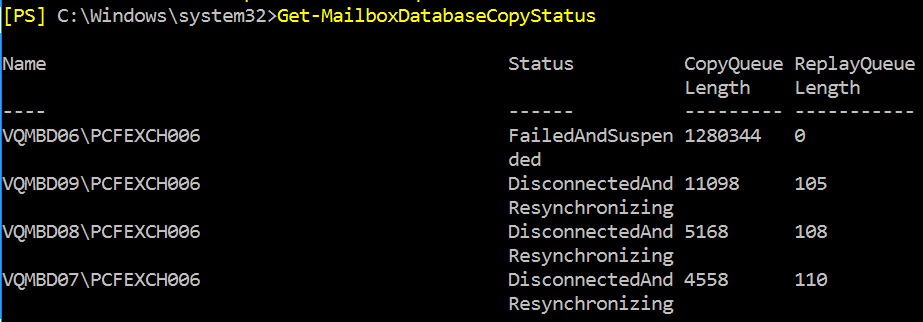
Although the Exchange databases were mounted and running on the DR server infrastructure, the replication state was in a failed state at the primary site. Running a Get-MailboxDatabaseCopyStatus command showed all databases in a status of DisconnectedAndResynchronizing
All steps attempted to try to re-establish synchronization of the databases failed with various different error messages, even deleting the existing database files and trying to re-seed the databases failed, with most messages pointing to network connectivity issues.
Update-MailboxDatabaseCopy vqmbd06\pcfexch006 -DeleteExistingFiles
Confirm
Are you sure you want to perform this action?
Seeding database copy "VQMBD06\PCFEXCH006".
[Y] Yes [A] Yes to All [N] No [L] No to All [?] Help (default is "Y"):
The seeding operation failed. Error: An error occurred while performing the seed operation. Error: An error occurred
while communicating with server 'DCExchange'. Error: A socket operation was attempted to an unreachable network
10.50.3.15:64327 [Database: VQMBD06, Server: pcfexch006.xxxxx.com]
+ CategoryInfo : InvalidOperation: (:) [Update-MailboxDatabaseCopy], SeedInProgressException
+ FullyQualifiedErrorId : [Server=PCFEXCH006,RequestId=e0740b4a-7b94-42f5-b3ad-7ee42632f9c4]
[FailureCategory=Cmdlet-SeedInProgressException] 2D10AE04,Microsoft.Exchange.Management.SystemConfigurationTasks.UpdateDatabaseCopy
+ PSComputerName : pcfexch006.xxxxx.comLooking carefully at the error message, the error says: A socket operation was attempted to an unreachable network 10.50.3.15:64327
Very strange, as when a network test was run, no errors occurred with connecting to that IP and TCP port.
Test-NetConnection -ComputerName DCExchange -Port 64327
ComputerName : DCExchange
RemoteAddress : 10.50.3.15
RemotePort : 64327
InterfaceAlias : Ethernet
SourceAddress : 10.50.2.42
TcpTestSucceeded : TrueWhen the test command Test-ReplicationHealth was run, the ClusterNetwork state was in a failed state:
PCFEXCH006 ClusterNetwork *FAILED* On server 'PCFEXCH006' there is more than one network interface
configured for registration in DNS. Only the interface used for
the MAPI network should be configured for DNS registration.
Network 'MapiDagNetwork' has more than one network interface for
server 'pcfexch006'. Correct the physical network configuration
so that each Mailbox server has exactly one network interface
for each subnet you intend to use. Then use the
Set-DatabaseAvailabilityGroup cmdlet with the -DiscoverNetworks
parameters to reconfigure the database availability group
networks.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
The Failover Cluster Manager was checked, but no errors were found, and the networks in question were “Up”, and in green status.
Looking further at the output of the Test-ReplicationHealth shows that the current state is “Misconfigured”, so let’s see how that replication traffic is configured. The following shows the output of Get-DatabaseAvailabilityGroupNetwork
RunspaceId : 57e140b2-15ad-4822-9f94-3e1b0d34f491
Name : MapiDagNetwork
Description :
Subnets : {{10.50.3.0/24,Up}, {10.50.2.0/24,Up}}
Interfaces : {{DCExchange,Up,10.50.3.15}, {pcfexch005,Up,10.50.2.36}, {pcfexch006,Up,10.50.2.42}}
MapiAccessEnabled : True
ReplicationEnabled : True
IgnoreNetwork : False
Identity : VarDAG2016\MapiDagNetwork
IsValid : True
ObjectState : New
RunspaceId : 57e140b2-15ad-4822-9f94-3e1b0d34f491
Name : ReplicationDagNetwork01
Description :
Subnets : {{192.168.100.0/24,Up}}
Interfaces : {{pcfexch005,Up,192.168.100.218}, {pcfexch006,Up,192.168.100.217}}
MapiAccessEnabled : False
ReplicationEnabled : True
IgnoreNetwork : False
Identity : VarDAG2016\ReplicationDagNetwork01
IsValid : True
ObjectState : New
An attempt was done to reset the network state by disabling the automatic configuration and re-enabling it with the following commands:
Set-DatabaseAvailabilityGroup VarDAG2016 -ManualDagNetworkConfiguration $true
Set-DatabaseAvailabilityGroup VarDAG2016 -ManualDagNetworkConfiguration $falseNo change, and the seed attempt failed again.
An attempt to remove the Backup network (Here named “ReplicationDagNetwork01“) from the replication traffic was done with the following commands:
Set-DatabaseAvailabilityGroup VarDAG2016 -ManualDagNetworkConfiguration $true
Set-DatabaseAvailabilityGroupNetwork -Identity VarDAG2016\ReplicationDagNetwork01 -ReplicationEnabled:$falseNo change was seen, and the seed attempt failed.
Looking further at the what options the command had, the “IgnoreNetwork” option was used:
Set-DatabaseAvailabilityGroup VarDAG2016 -ManualDagNetworkConfiguration $true
Set-DatabaseAvailabilityGroupNetwork -Identity VarDAG2016\ReplicationDagNetwork01 -ReplicationEnabled:$false -IgnoreNetwork:$true
Still no change, so I set back the autoconfiguration with the command:
Set-DatabaseAvailabilityGroup VarDAG2016 -ManualDagNetworkConfiguration $falseRunning Get-DatabaseAvailabilityGroupNetwork | fl showed no visible change, but the Site-to-Site tunnel showed a massive uptick in usage, so I ran the Get-MailboxDatabaseCopyStatus command, and it showed all databases that were in a status of DisconnectedAndResynchronizing synchronizing! I retried the reseed process, and it worked!
I’m not sure why the Set-DatabaseAvailabilityGroupNetwork command showed no visible changes, but it’s obvious the changes did occur, that the replication was disabled over the BackupNet (192.168.100.x) and forced over the correct network.