In the process of troubleshooting some Azure Local, a Microsoft developer did the following keyboard shortcut command that I feel should have a short article about it.
I’ve often used the “dash ‘-‘ tab” function to cycle through the parameters of a commandlet, however, there’s a way of displaying all the parameters on the screen so you can go to them with an arrow key! Use Ctrl+Spacebar!
It uses Intellisense to display all available parameters!
I had a 16 node Azure HCI 23H2 based cluster that refused to get past the initial update, after several undocumented resolutions, decided to put together a series of posts with the solutions!
There is good documentation at the Microsoft site with all requirements for HCI clusters, be it Azure Stack, or Windows Storage Spaces Direct (S2D) clustering, so I will not be going into that, however, I came across the following challenges even though all solutions were properly configured.
16 Node clusters based on 23H2, with 100Gb NICs and fabric
Nodes randomly dropping out of cluster
Nodes were unstable, with disks going offline, nodes going offline, lots of random behavior not allowing the initial update to succeed.
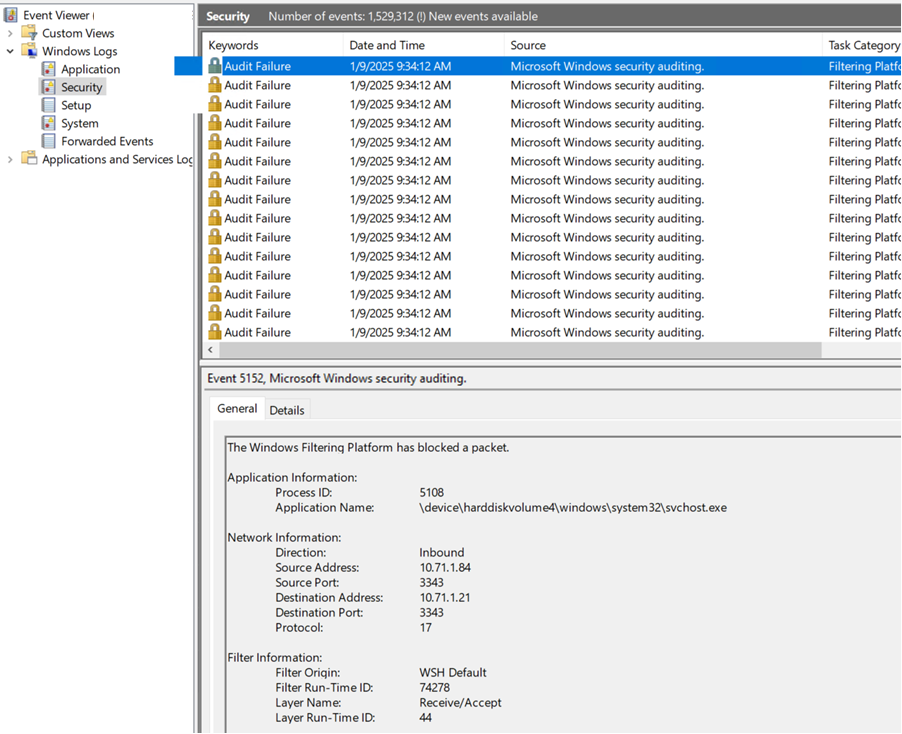
When looking at the Security Event log of the nodes, the following event ID 5152 and other 51xx occurred constantly on all nodes of the cluster:
Looking at this log entry, I see that cluster SMB VLAN 711 & 712, Protocol 17 (UDP), Port 3343 to and from the nodes is blocked by “WSH Default” (Windows Service Hardening), which to me, explained why nodes had disks going offline, and as a result, nodes going offline.
I created Inbound and Outbound manual rules to allow that traffic, however, the rule was ignored by all systems.
Most of these blog articles are fixes I came up with, and I wish I could claim this one, but in the case, I have to give credit to where credit is due, it was the Microsoft engineer Wai Kong who had me try something that to me, was a huge learning experience, and was so ‘out there’, I needed to learn how to the solution was found, which I will explain at the end.
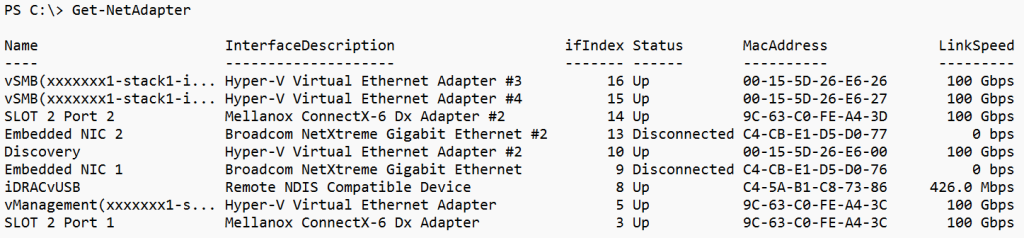
We checked the NICs in question using Get-NetAdapter, as shown in the following figure:
Next, we checked the full settings of the vSMB NIC with the Get-NetIPInterface command:
Note the “Dhcp” setting is ‘enabled’? Well, even though this vNIC has static addressing, the svchost.exe application was trying to get/use the DHCP configuration, and as a result, bypassing the firewall allow rule. How/Why? That’s a conversation for another time, the solution here was to disable it on all the nodes on the 2 ports in question (*Port 1 and *Port 2)
Here’s how I disabled it using the Set-NetIPInterface command:
Once this was run on all 16 nodes, (You can run the command remotely with Enter-PSSession) the errors stopped in System Event Logs, disks stopped going offline, and node stability was established!
How was this discovered?
The event tells you which process generates the message, tools are used to check the modules (DLLs or exe) in the process. In this case, the DHCP related DLL in the system was calling for the DHCP client service.
EVERY company should have a “secret generalist.” Someone who is comprehensively skilled, low ego, incredibly strategic, and who jumps in whenever and wherever needed. I used to call this a “Seal Team Member” for the CEOs I supported. This person operates with full autonomy, reports to the CEO, and will always be that one employee who bypasses all of the BS, needless meetings, and hierarchical shenanigans with the sole intent to get things done in light speed. When a CEO has an idea, it gets handed off to this person to quickly bring it to MVP. NO this is not an EA. NO this is not a Chief of Staff. This is someone who executes quickly and brings a CEO’s “shower thought” to a workable beta. My last company had a couple of these “ninjas” who, I believe, are responsible for the insane speed at which the company iterates…their trademark. They were highly trusted by the CEO, completely misunderstood by the general population, and as stealth as special ops soldiers.
Teams get too bogged down in process. Especially, in Engineering. Especially at management level. And far too many projects collect dust because the “shower thought” has to go through a whole JIRA queue to be vetted by a bunch of management, people assigned/reassigned to work on it, and having to answer a bunch of questions in weeks of meetings when you could literally hand it to someone and have them bring it to MVP in a day or two.
The CEOs who listened to me and implemented this always were ahead of the game. The ones who didn’t…well. I haven’t heard from them, either.
The above was recently posted by Phoenix Normand, and I so agree with it, I re-posted it verbatim
Hire a generalist for your CEO. Pay them well. Thank me later.
I’m usually this person as a consultant and EA. The trick actually isn’t to bypass company processes, PMO and Governance, Agile (what a misnomer if there ever was one) orgs, etc. You have to work with those organizations enough in advance to have them trust you when you want to work something in and you need to do it rapidly. When you’re doing this, you’re arriving and leaving as naturally and unremarkably, for if is an event it defeats the purpose.
Stealth is one way of doing it but I prefer total and unquestionable transparency, and I find that way takes quite a bit less energy. Still, you need that stealth skillset too because not everything is public knowledge and you’re not the right comms channel for things that can shake people up.
Now that we’ve gone over some a couple basics, I wanted to go through some of the features Azure AD has built in which not only blow on-premise AD away, but also show why a push to utilize it over it’s predecessor is vital for the modern workspace.
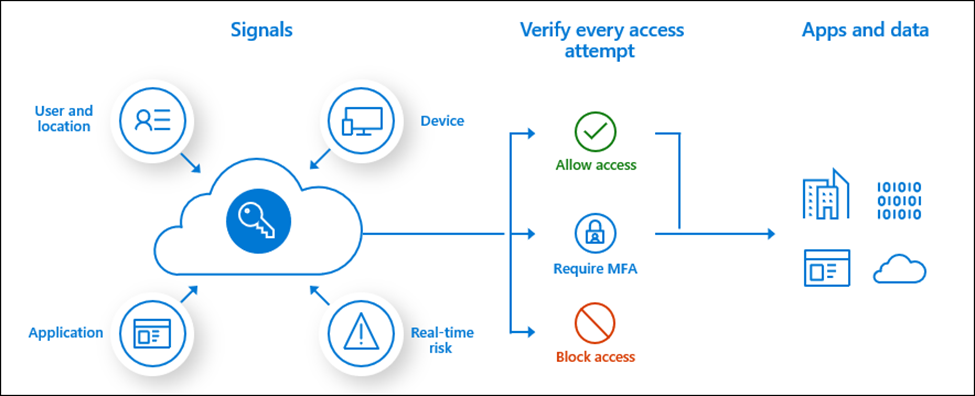
The modern security perimeter now extends beyond an organization’s network to include user and device identity. Organizations can use identity-driven signals as part of their access control decisions.
Conditional Access brings signals together, to make decisions, and enforce organizational policies. Azure AD Conditional Access is at the heart of the new identity-driven control plane.
I’ve especially seen post-Covid, with the workspace being more dispersed, the two goals I see most commonly requested are to:
Empower users to be productive wherever and whenever
Protect the organization’s assets
In my opinion, using Azure AD Conditional Access policies to apply the right access controls when needed is one of the strongest controls available for keeping the organization secure.
Signals that Conditional Access can use when making decisions include:
User or group memberships
Note: Dynamic memberships are super powerful here, drastically lowering the support overhead with utilizing this control!
IP Location info
Specific Device
Based on application
A.I. – like, by using real-time and calculated risk detection
Note: This one is cool, as integration with AzAD Identity Protection allows the identity of risky sign-in behavior, and you can then force users to go through some of the options talked about in Part 1
Conditional Access is very powerful, however, I would recommend that it initially be implemented in “report only” mode. – Thankfully, for many obvious reasons, an excellent option.
Entitlement Management
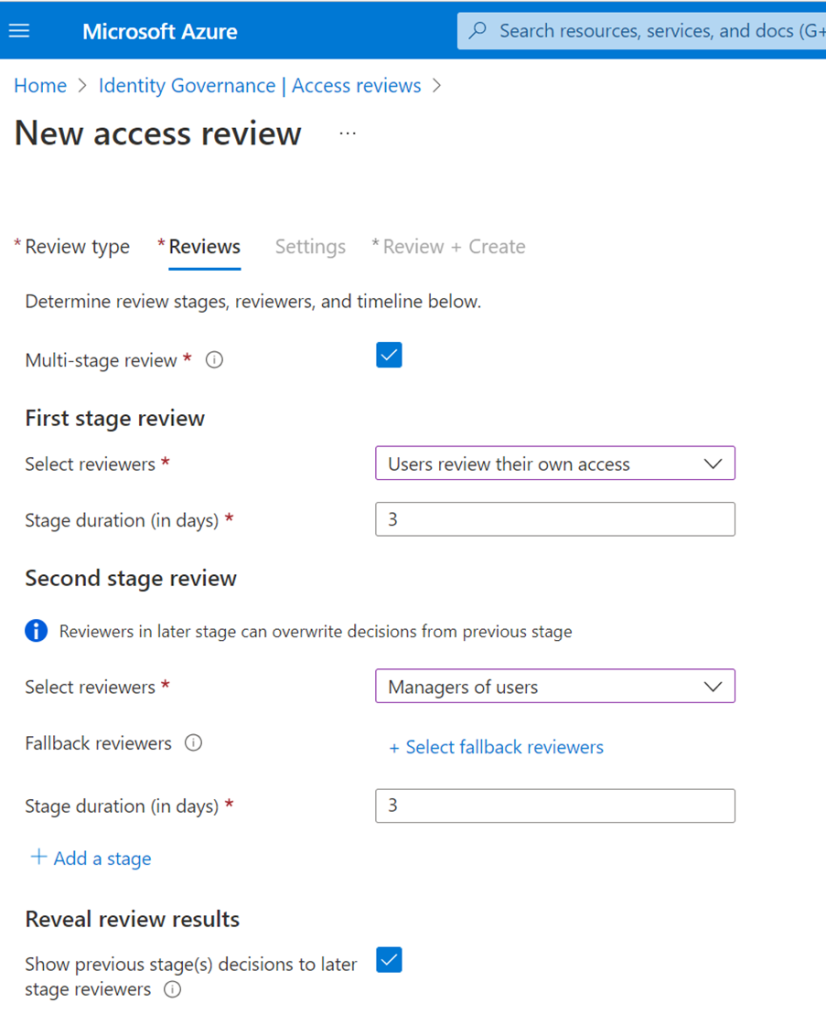
Continuing in the same theme, either static, or automatic assignments of access packages can be created in Entitlement Management, which now include multi-stage reviews.
Access reviews can be built in sequential stages, each with their own set of reviewers and configurations, making it easy to design more efficient reviews for the resource owners and auditors by reducing the number of decisions each reviewer is accountable for.
Note: In the following sample, I have a third party application added as “Application”, the reason it shows up is because it is an Enterprise App registered in my Azure tenant, one can only imagine the possibilities here!
Up to three stages can be specified, in addition, you can define whether earlier stage decisions should be revealed to later-stage reviewers.
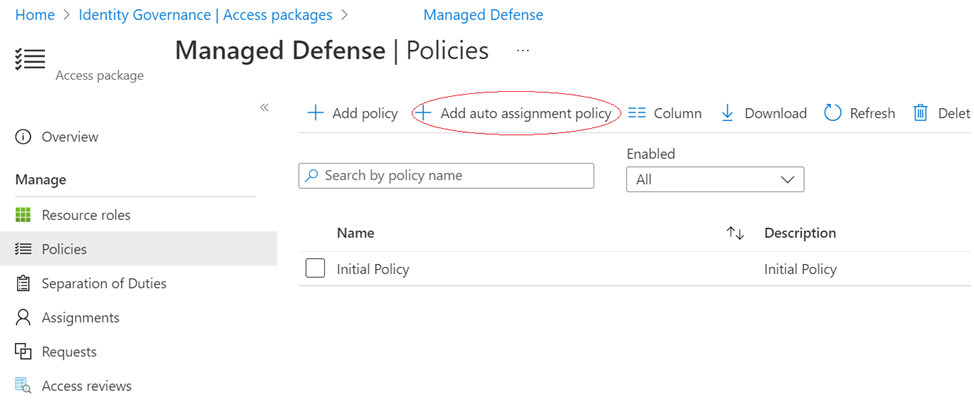
Automatic assignment of access policies
Azure AD now adds and removes users’ access across groups, Teams, SharePoint sites, and applications as their attributes change (such as when someone joins, moves between departments, etc.). The inclusion of this policy in an access package simplifies managing at scale; users don’t need to make requests, which not only ensures their access doesn’t remain longer than necessary, but also does so without the need for administrative interaction when someone moves teams.
Here’s a screenshot example for a policy I’ve got
In this example, the rule is based on the attributes of the user, in this case department. Azure AD will automatically begin creating resource assignments for those users who meet the rule, without the need to request.
In addition to what be done with dynamic groups, we can also use entitlement management with automatic assignment policies for:
Managing access across multiple resources, including applications, SharePoint Online sites, existing Azure AD groups and Teams, and groups that are provisioned to on-premises AD.
Managing access with a combination of policies to have both rules (for instance, members in a department) and exceptions so that the exceptions can be regularly reviewed and removed, if no longer needed
More automation of tasks across applications through entitlement management’s custom extensions, by running workflows when users receive or lose assignments
This weekend I successfully passed the SC-100 certification, with it have now achieved my second Expert level cert, the Cybersecurity Architect certification from Microsoft.
Learned a ton, and looking at the exam score, I overstudied on governance, but that’s what I’m interested in, and yes, it’s helped a ton with furthering my knowledge with Azure security infrastructure and design!
This series of articles is to document steps to be taken to transition from an on-premise Active Directory footprint, and migrate the workloads to Azure AD.
A typical migration has the following stages:
Discovery: Find out what is currently in the environment
Pilot: Deploy new cloud capabilities to a small subset of users, applications, and devices
Scale Out: Expand the pilot to complete the transition
Cut-over: Stop using the on-premises authentication
Users and Groups
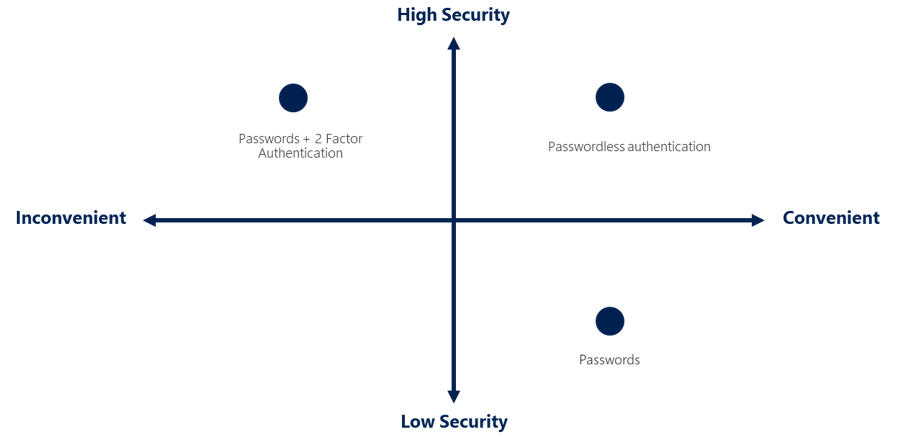
Microsoft highly recommends a passwordless environment, due to as is depicted in the following graphic, is both highly secure, and convenient.
In my experience, users correctly following secure practices either make or break security initiatives, thus, in my opinion, convenience is crucial
Industry authentication standards rely on one of the following:
Something you Know:
Passwords are great, but unless a vault is used, it is common to use the same, or variation for many personal accounts. Highly vulnerable in modern times, as environments are often compromised, with credentials getting exposed to public sites. The equivalent of writing credentials down on paper and other people finding it.
Something you Have:
Removes the problem of forgetting something you know, but is vulnerable to the object being lost or stolen.
Something you Are:
Much harder to lose a fingerprint than a wallet, however, while this is getting better, historically, biometric sensors can be fairly expensive (cost and support) and have accuracy issues.
Due to the fact each authentication methods have their vulnerabilities, a combination of them is much stronger, hence the modern term “Multi-Factor Authentication” (MFA)
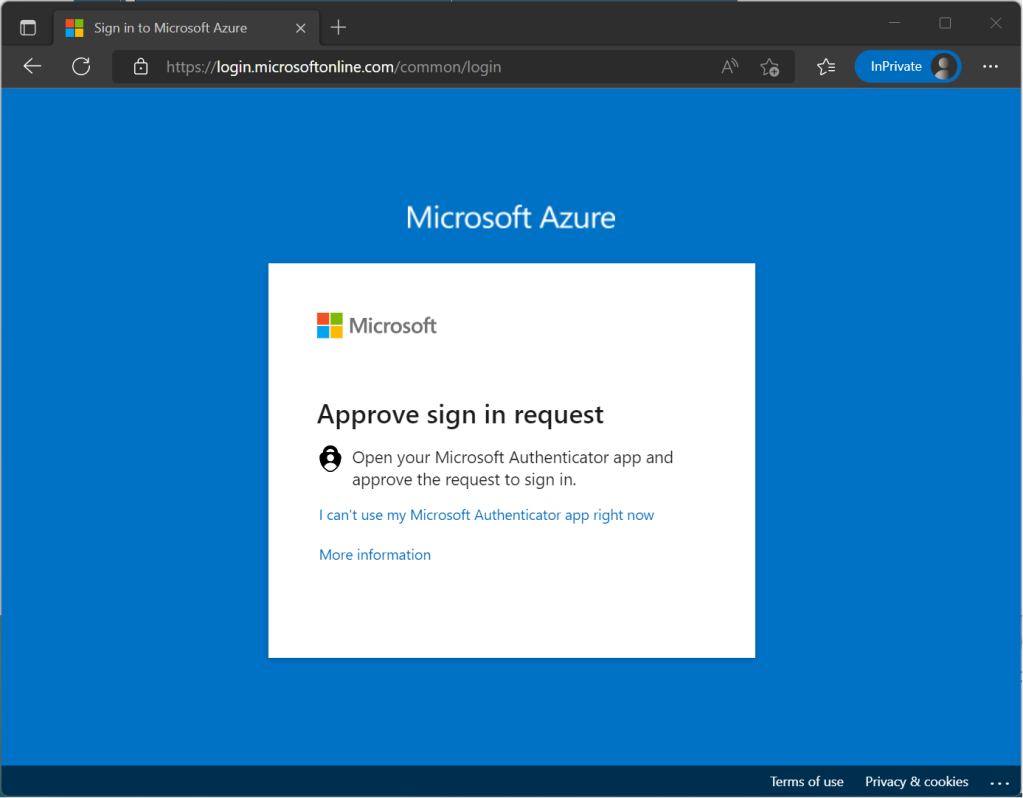
Here’s an example of using the Authenticator App as a convenient multi-factor authentication option in addition to a password.
The Authenticator App turns any iOS or Android phone into a strong, passwordless credential. Users can sign in to any platform or browser by getting a notification to their phone, matching a number displayed on the screen to the one on their phone, and then using their biometric (touch or face) or PIN to confirm.
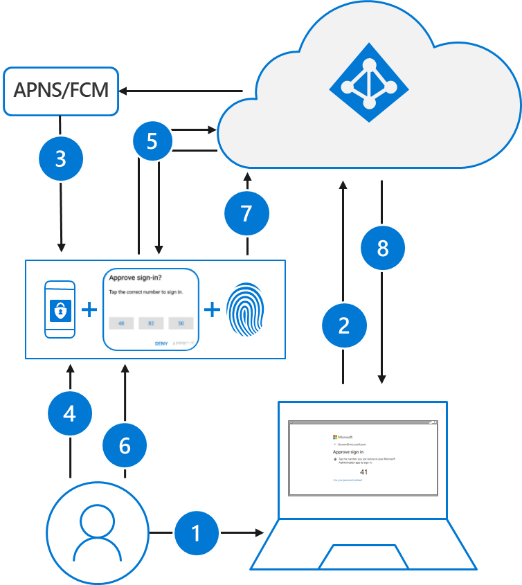
Passwordless authentication using the Authenticator app follows the same basic pattern as Windows Hello for Business. It’s a little more complicated as the user needs to be identified so that Azure AD can find the Authenticator app version being used:
The user enters their username.
Azure AD detects that the user has a strong credential and starts the Strong Credential flow.
A notification is sent to the app via Apple Push Notification Service (APNS) on iOS devices, or via Firebase Cloud Messaging (FCM) on Android devices.
The user receives the push notification and opens the app.
The app calls Azure AD and receives a proof-of-presence challenge and nonce.
The user completes the challenge by entering their biometric or PIN to unlock private key.
The nonce is signed with the private key and sent back to Azure AD.
Azure AD performs public/private key validation and returns a token.
Password Self-Service
Until an MFA environment is in place, migrating to Azure’s password self-service (SSPR) gives users the capability of managing their own password resets, which not only greatly helps with the “convenience” point I made above, but in most cases, tremendously decreases help desk support calls.
The following authentication methods are available for SSPR:
Mobile app notification
Mobile app code
Email
Mobile phone
Office phone (available only for tenants with paid subscriptions)
Security questions
Users can only reset their password if they have registered an authentication method that the administrator has enabled.
On-premises integration
With a hybrid environment, first install and configure the sync agent to be capable of enabling password writeback, once that is complete, you can configure Azure AD Connect to write password change events back from Azure AD to the on-premises directory.
In addition, the following options are available:
Users can unlock accounts without resetting their password
Possibly due to specific governance needs, or perhaps maintaining a specific infrastructure in your cloud environment, you might want to lock out standard build capability for a group of users.
In the following example, I had a request to remove the ability of creating new Resource Groups in Azure to most users regardless of authorization levels, here is the example of how to do so with Microsoft Graph permission sets.
I created a custom Azure role that defined what can be done, and what can’t be done, looking at a the empty role JSON file, you can see there are “Actions” and “NotActions” sections:
With this example, we are targeting Resource Groups, so we will use:
Microsoft.Resources/subscriptions/resourceGroups
Step 2: Find the available permissions. With this case, we want to restrict creating or modifying resource groups, so it makes sense to add to the deny section the “write” permission.
Once you’ve created the role definition, import it into your Azure subscription and assign the role to the necessary users, they’ll get the “You do not have permissions to create resource groups under subscription” message when trying to create a new group.
I’ve been pretty quiet as of late, however, not standing still. After a ton of heavy studying, achieved the Azure Security Engineer certification from Microsoft.
Learned a ton, especially on governance and Azure security design!
Happy New Year from Microsoft to Exchange on-premise users!
Due to a pretty bad MSExchange Antimailware update that was sent out, As a result of bad code, the MSExchange Antimalware engine broke, and Exchange will not process email.
The following errors are found in the event viewer of the affected systems:
Event 5801:
The anti-malware agent encountered an error while scanning. MessageId: <guid@domain.net> Message sent: 1/1/2022 5:05:21 PM From: <> Size: 12503 Bytes Error: Microsoft.Filtering.ScanAbortedException: Exception of type 'Microsoft.Filtering.ScanAbortedException' was thrown.
at Microsoft.Filtering.InteropUtils.ThrowPostScanErrorAsFilteringException(WSM_ReturnCode code, String message)
at Microsoft.Filtering.FilteringService.EndScan(IAsyncResult ar)
at Microsoft.Exchange.Transport.Agent.Malware.MalwareAgent.OnScanCompleted(IAsyncResult ar)
Event 5300:
The FIP-FS "Microsoft" Scan Engine failed to load. PID: 19120, Error Code: 0x80004005. Error Description: Can't convert "2201010009" to long.
Event 1106:
The FIP-FS Scan Process failed initialization. Error: 0x80004005. Error Details: Unspecified error
The current fix is to disable the anti-malware scan module with the following Exchange system script:
Create Office 365 mailbox folders and advanced mailbox rules with Powershell and MS Graph
Recently, a request came through to create some email messaging processing for various Office 365 users, which involved creating some folder structure in mailboxes of a list of users, and creating a message rule that had some different criteria based on email message attributes.
The needs were:
Create a root folder
Create a folder inside that root folder
Create a rule:
Check the message Header for From address
Check for custom Header information
Move message to previously created subfolder
Finally, make sure there was no second mailbox rule created if already existed.
The New-MailboxFolder Powershell command works perfectly if the folder needed is for your own mailbox, if you want to run it against others, there is no current Powershell commandlet, so custom code must be created. While there are some basic examples out there, there was no comprehensive script anyone has published as of yet, so here is one I came up with.
For brevity purposes, I won’t go into detail the process that’s required to authenticate in order to run scripts against your environment, as there are quite a few resources available easily found by your favorite search engine, so I will skip over that process, and explain the “how to figure out what you need to accomplish with Powershell using MS Graph.”
The key part of this article is not to show how fancy of a script I can write (disclaimer: the fancy spacing is from Visual Studio Code, use it!), but rather, how to get at the MS Graph API and syntax required to do the tremendous amount of capabilities that it’s got access to. I figured by throwing up a script that does quite a few different things that were previously only available if you ran several different scripts one after another (and hoped nothing broke), here’s an example of doing several different things easily using Powershell against the MS Graph API.