I had a 16 node Azure HCI 23H2 based cluster that refused to get past the initial update, after several undocumented resolutions, decided to put together a series of posts with the solutions!
There is good documentation at the Microsoft site with all requirements for HCI clusters, be it Azure Stack, or Windows Storage Spaces Direct (S2D) clustering, so I will not be going into that, however, I came across the following challenges even though all solutions were properly configured.
16 Node clusters based on 23H2, with 100Gb NICs and fabric
Nodes randomly dropping out of cluster
Nodes were unstable, with disks going offline, nodes going offline, lots of random behavior not allowing the initial update to succeed.
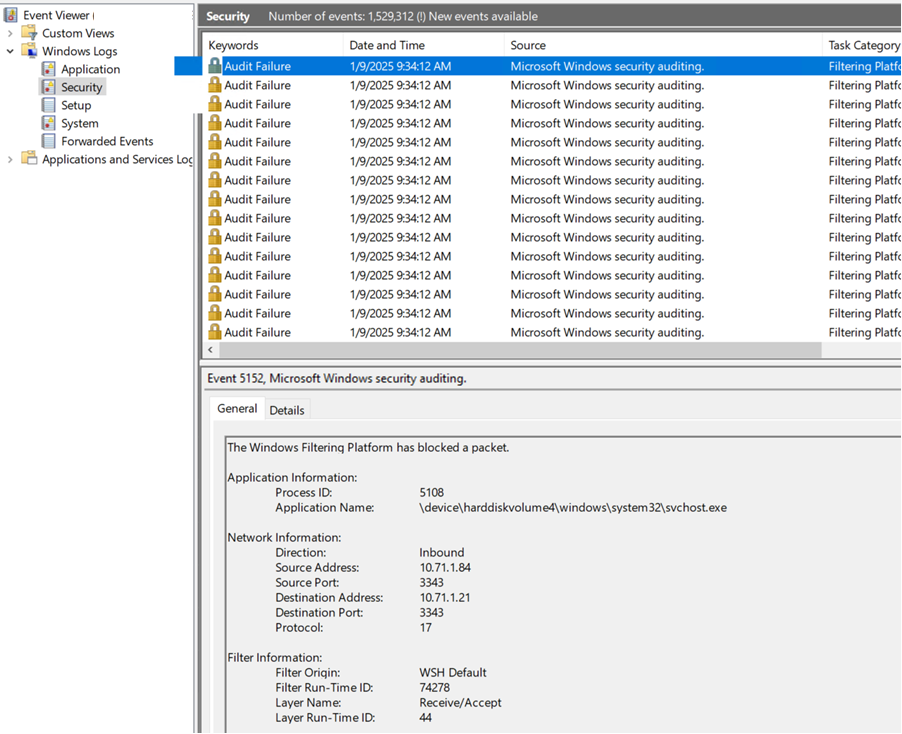
When looking at the Security Event log of the nodes, the following event ID 5152 and other 51xx occurred constantly on all nodes of the cluster:
Looking at this log entry, I see that cluster SMB VLAN 711 & 712, Protocol 17 (UDP), Port 3343 to and from the nodes is blocked by “WSH Default” (Windows Service Hardening), which to me, explained why nodes had disks going offline, and as a result, nodes going offline.
I created Inbound and Outbound manual rules to allow that traffic, however, the rule was ignored by all systems.
Most of these blog articles are fixes I came up with, and I wish I could claim this one, but in the case, I have to give credit to where credit is due, it was the Microsoft engineer Wai Kong who had me try something that to me, was a huge learning experience, and was so ‘out there’, I needed to learn how to the solution was found, which I will explain at the end.
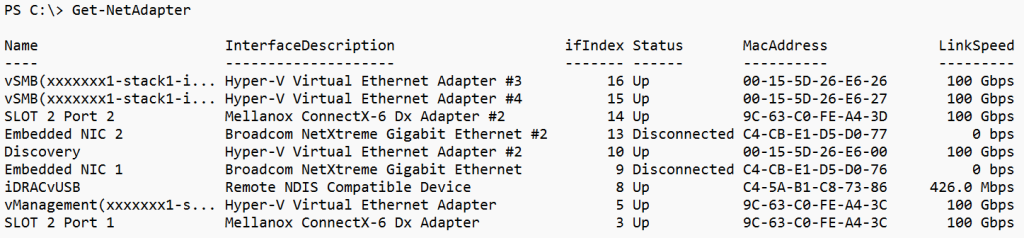
We checked the NICs in question using Get-NetAdapter, as shown in the following figure:
Next, we checked the full settings of the vSMB NIC with the Get-NetIPInterface command:
Note the “Dhcp” setting is ‘enabled’? Well, even though this vNIC has static addressing, the svchost.exe application was trying to get/use the DHCP configuration, and as a result, bypassing the firewall allow rule. How/Why? That’s a conversation for another time, the solution here was to disable it on all the nodes on the 2 ports in question (*Port 1 and *Port 2)
Here’s how I disabled it using the Set-NetIPInterface command:
Once this was run on all 16 nodes, (You can run the command remotely with Enter-PSSession) the errors stopped in System Event Logs, disks stopped going offline, and node stability was established!
How was this discovered?
The event tells you which process generates the message, tools are used to check the modules (DLLs or exe) in the process. In this case, the DHCP related DLL in the system was calling for the DHCP client service.
I recently came across a scenario, where an Exchange environment that had been configured in a Best Practice state had failed over to the DR site due to an extended network outage at the primary production site, and was unable to re-seed back and fail back over.
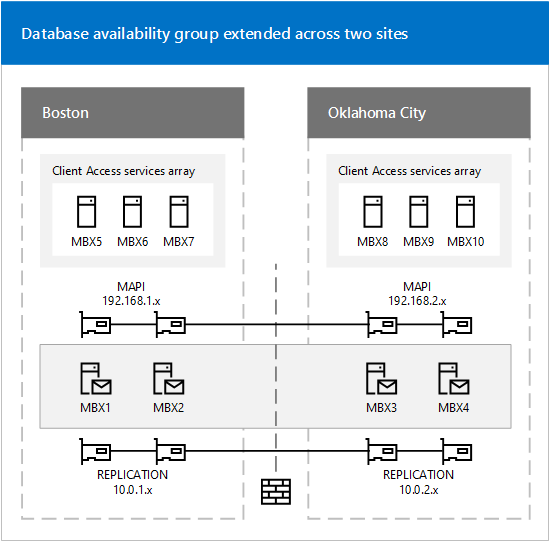
The environment was configured very similar as described in the Deploy HA documentation by Microsoft, and had it’s DAG configured across two sites:
Stock example showing DR site relationship
Instead of the “Replication” network that is shown in the above graphic, the primary site had a secondary network (subnet 192.168.100.x) where DPM backup services ran on, the DR site did not include a secondary network.
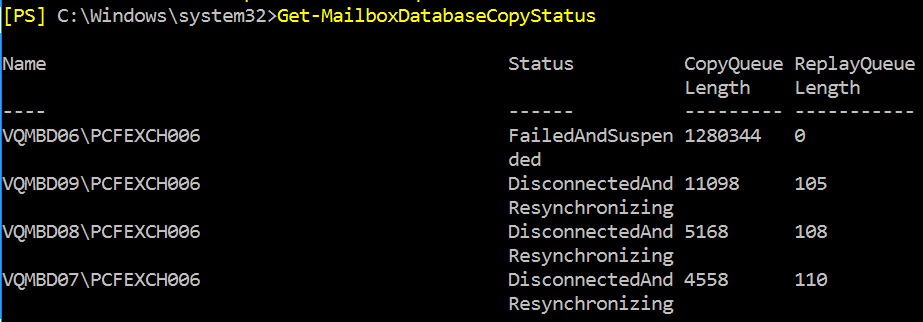
Although the Exchange databases were mounted and running on the DR server infrastructure, the replication state was in a failed state at the primary site. Running a Get-MailboxDatabaseCopyStatus command showed all databases in a status of DisconnectedAndResynchronizing
DisconnectedAndResynchronizing state
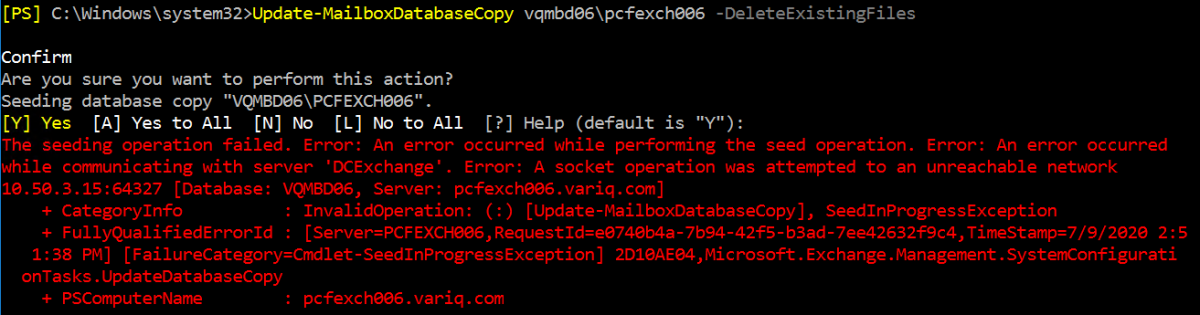
All steps attempted to try to re-establish synchronization of the databases failed with various different error messages, even deleting the existing database files and trying to re-seed the databases failed, with most messages pointing to network connectivity issues.
Update-MailboxDatabaseCopy vqmbd06\pcfexch006 -DeleteExistingFiles
Confirm
Are you sure you want to perform this action?
Seeding database copy "VQMBD06\PCFEXCH006".
[Y] Yes [A] Yes to All [N] No [L] No to All [?] Help (default is "Y"):
The seeding operation failed. Error: An error occurred while performing the seed operation. Error: An error occurred
while communicating with server 'DCExchange'. Error: A socket operation was attempted to an unreachable network
10.50.3.15:64327 [Database: VQMBD06, Server: pcfexch006.xxxxx.com]
+ CategoryInfo : InvalidOperation: (:) [Update-MailboxDatabaseCopy], SeedInProgressException
+ FullyQualifiedErrorId : [Server=PCFEXCH006,RequestId=e0740b4a-7b94-42f5-b3ad-7ee42632f9c4]
[FailureCategory=Cmdlet-SeedInProgressException] 2D10AE04,Microsoft.Exchange.Management.SystemConfigurationTasks.UpdateDatabaseCopy
+ PSComputerName : pcfexch006.xxxxx.com
Looking carefully at the error message, the error says: A socket operation was attempted to an unreachable network 10.50.3.15:64327
Very strange, as when a network test was run, no errors occurred with connecting to that IP and TCP port.
When the test command Test-ReplicationHealth was run, the ClusterNetwork state was in a failed state:
PCFEXCH006 ClusterNetwork *FAILED* On server 'PCFEXCH006' there is more than one network interface
configured for registration in DNS. Only the interface used for
the MAPI network should be configured for DNS registration.
Network 'MapiDagNetwork' has more than one network interface for
server 'pcfexch006'. Correct the physical network configuration
so that each Mailbox server has exactly one network interface
for each subnet you intend to use. Then use the
Set-DatabaseAvailabilityGroup cmdlet with the -DiscoverNetworks
parameters to reconfigure the database availability group
networks.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
The Failover Cluster Manager was checked, but no errors were found, and the networks in question were “Up”, and in green status.
Looking further at the output of the Test-ReplicationHealth shows that the current state is “Misconfigured”, so let’s see how that replication traffic is configured. The following shows the output of Get-DatabaseAvailabilityGroupNetwork
Running Get-DatabaseAvailabilityGroupNetwork | fl showed no visible change, but the Site-to-Site tunnel showed a massive uptick in usage, so I ran the Get-MailboxDatabaseCopyStatus command, and it showed all databases that were in a status of DisconnectedAndResynchronizing synchronizing! I retried the reseed process, and it worked!
I’m not sure why the Set-DatabaseAvailabilityGroupNetwork command showed no visible changes, but it’s obvious the changes did occur, that the replication was disabled over the BackupNet (192.168.100.x) and forced over the correct network.
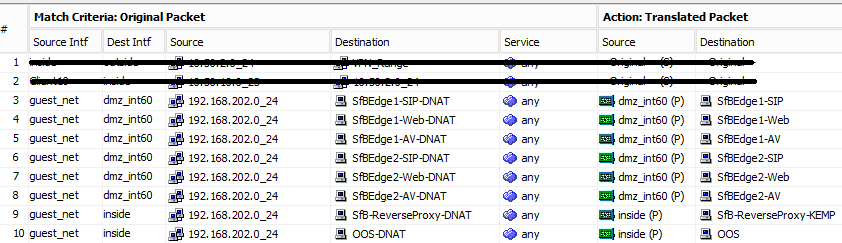
The corporate office has an environment where there is a separate “guest” network for vendors, visitors, etc. that can use their own devices, to use internet services through Wi-Fi.
Due to the fact some internal services are needed such as joining internal Audio/Video conferences, and access to collaborative services, we had a requirement that access to those services be available through this semi-public network that is “external”, i.e. uses external DNS resolution, but is still “inside” the firewall boundary as shown below.
To spell it out, we had the following infrastructure:
Internal services only accessible from inside the corporate network and internal devices.
External services accessible from outside the corporate network.
Guest network with external/public DNS resolution.
The requirements are as follows:
Internal services accessible externally if secured with boundary extending services, primarily Microsoft Direct Access, or if explicitly approved, Cisco VPN software.
Skype for Business availability for Guest Wi-Fi to join conferences and collaboration.
SharePoint services (specifically Office Online Server) for collaboration access from Guest Wi-Fi.
Destination for the Skype for Business services is the “inside” DMZ interface, as in this case, the DMZ is sandwiched, has an internally facing network, and an externally facing network, or wherever the service resides, as some services are on the “services” network.
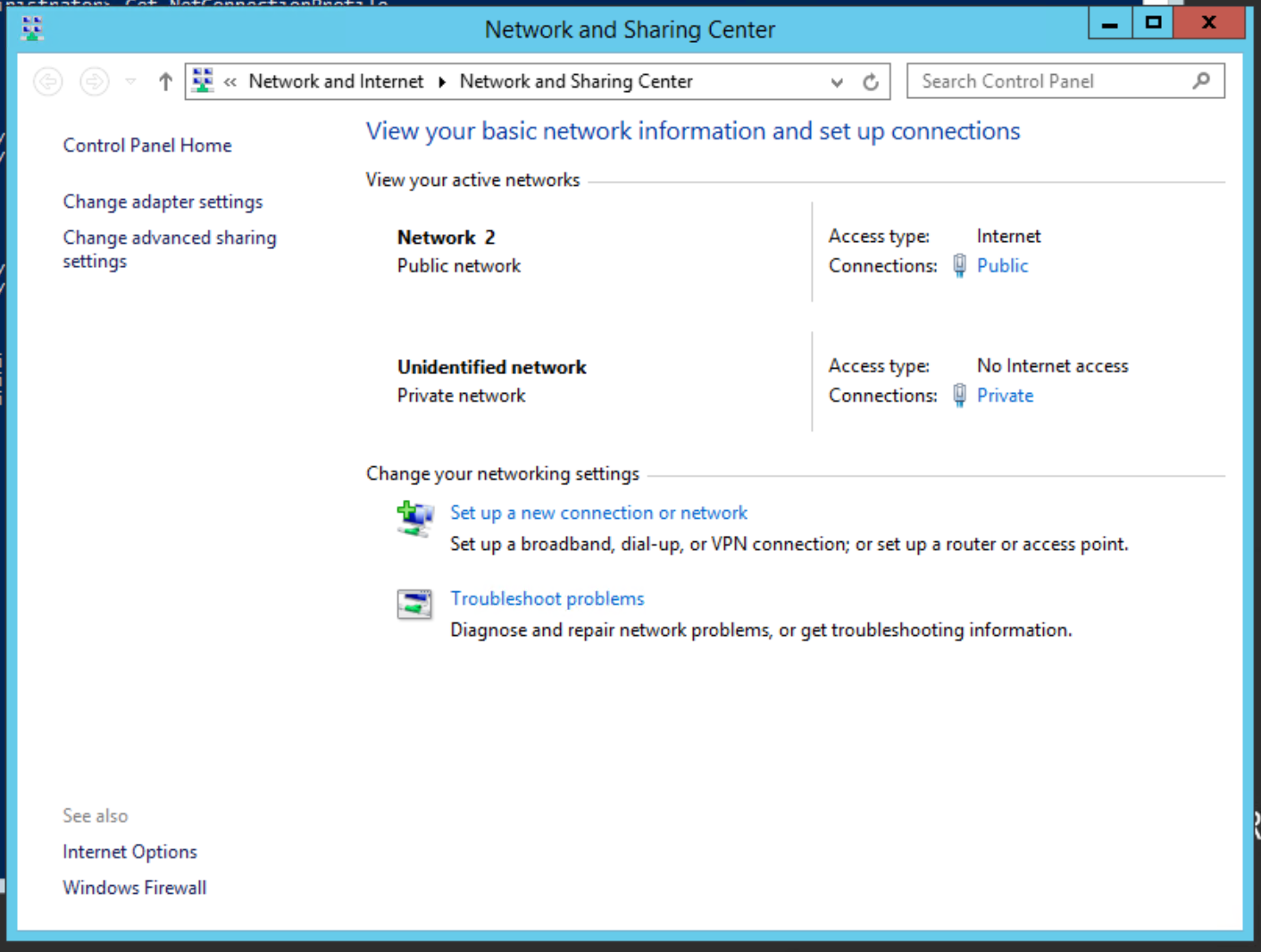
I recently had a non-domain joined edge Windows 2016 machine with two separate NICs that I needed to set different Windows Firewall settings to. Why? For instance, I wanted to allow RDP for the Internal NIC, and not allowing it for the External one, etc. The problem was, the NICs were set with the wrong network profile, the external public facing one was set to Private, and the other was reversed as shown in the following screen capture:
New with Windows Server 2012 and higher, to change the network profile, PowerShell v4 cmdlets need to be used! Those cmdlets are:
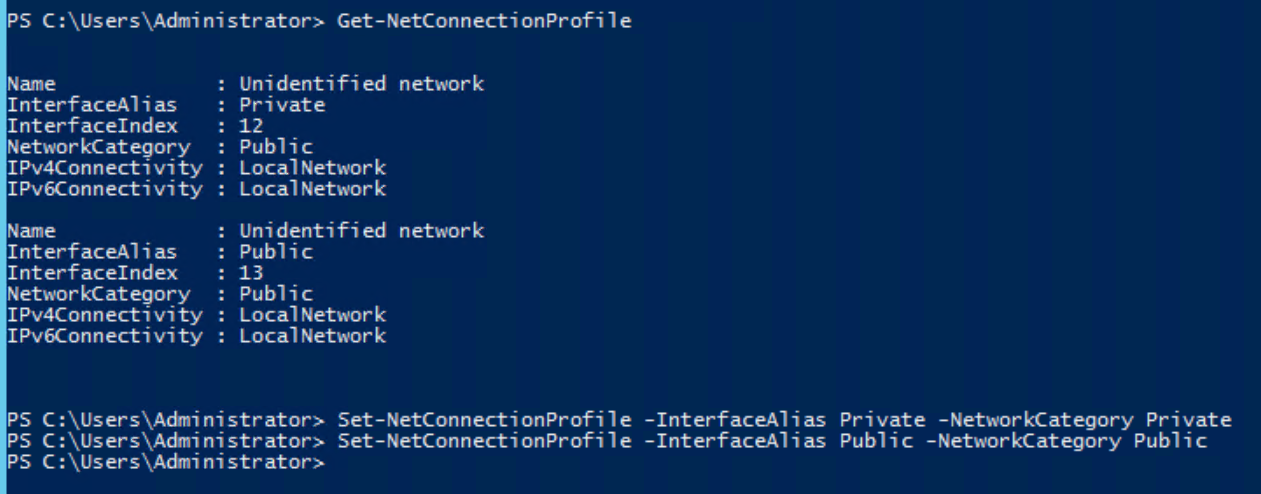
Get-NetConnectionProfile
Set-NetConnectionProfile
Here are the results with the “Get” command:
We can see the results are reversed, as the “Internet” connection has the “Private” designation, thus the wrong Windows Firewall profile is assigned to it.
To fix that, we run the “Set” command as shown in the bottom of the capture above, and the correct firewall profile is assigned!
Note: I named the external facing NIC “Public”, and the internal facing one “Private”. You can name it whatever you’d like, and identify it with the -InterfaceAlias property.
The default profile in Windows Server 2012+ is Public. It automatically changes when you join the server to the Domain. In my instance, I was not joining this server to a Domain, and thus had to set it manually, on top of that, in this instance, the automatic designation was configured incorrectly.