Fix a madding “Invalid password” error when trying to use an Azure service that uses Azure AD DS as it’s authentication
I hope this helps someone fix a madding “Invalid password” error when trying to use an Azure service that uses Azure AD DS as it’s authentication with a synced account from on-premise AD.
With a recent implementation of Windows Virtual Desktop, and interesting failure occurred with a set of users that were synchronized to Azure AD from an on-premise AD environment.
The environment was one where there was no longer an Azure AD Connect configuration in place, in fact, the on-premise AD environment was no longer available. All users were using Office 365 services without any issues, and Azure AD Domain Services was implemented for new Azure services, one of them being WVD.
All WVD services were tested with the admin account that created the resources, and some test users created in Azure AD, however, when the group that needed to use the service tried to use it with their accounts, around half the necessary users could not log into the VM image.
After verifying all permissions were correctly assigned, and checking to see if there were any relevant differences between the accounts that were able to log on vs. the ones that were not, I noticed that all accounts were able to log on to the web URL, however after the initial logon to the service, the originally synced accounts were failing with an “invalid password” error, whereas the ones that were directly created in Azure succeeded. – Aha! This pointed me to the fact that the accounts seemed to be having some sort of Azure ADDS failure, as 365 services were not dependent on that.
Quite a few articles were read all over the place, with none being any help, so I went back to the basics, and went over the Azure AD to Azure AD DS synchronization guide much more methodical than I previously had.
I’ll cut to the chase, in the middle of that guide, the following statement is made: When a user is created in Azure AD, they’re not synchronized to Azure AD DS until they change their password in Azure AD.
This article is just a reminder to read event log errors carefully, as they tremendously help troubleshoot undocumented errors (which this blog is all about)
A Windows Virtual Desktop implementation kept having it’s Session host VMs randomly go to an Unavailable status, and after going through the full plethora of troubleshooting articles, I decided to take a closer look at the event error 3389:
Unable to retrieve DefaultAgent from registry: System.NullReferenceException: Object reference not set to an instance of an object.
at RDAgentBootLoader.BootLoaderSettings.get_DefaultAgentPath() in S:\src\RDAgent\src\RDAgentBootloader\BootLoaderSettings.cs:line 82
The above error doesn’t say much, and is pretty cryptic, but when we look at the detail pane, we get some better information:
Log Name: Application
Source: RDAgentBootLoader
Date: 12/11/2020 10:21:05 AM
Event ID: 3389
Task Category: None
Level: Error
Keywords: Classic
User: N/A
Computer: lis-wvd-0.xxxxxxx.com
Description:
Unable to retrieve DefaultAgent from registry: System.NullReferenceException: Object reference not set to an instance of an object.
at RDAgentBootLoader.BootLoaderSettings.get_DefaultAgentPath() in S:\src\RDAgent\src\RDAgentBootloader\BootLoaderSettings.cs:line 82
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="RDAgentBootLoader" />
<EventID Qualifiers="0">3389</EventID>
<Version>0</Version>
<Level>2</Level>
<Task>0</Task>
<Opcode>0</Opcode>
<Keywords>0x80000000000000</Keywords>
<TimeCreated SystemTime="2020-12-11T15:21:05.2207218Z" />
<EventRecordID>10136</EventRecordID>
<Correlation />
<Execution ProcessID="0" ThreadID="0" />
<Channel>Application</Channel>
<Computer>lis-wvd-0.xxxxxxxx.com</Computer>
<Security />
</System>
<EventData>
<Data>Unable to retrieve DefaultAgent from registry: System.NullReferenceException: Object reference not set to an instance of an object.
at RDAgentBootLoader.BootLoaderSettings.get_DefaultAgentPath() in S:\src\RDAgent\src\RDAgentBootloader\BootLoaderSettings.cs:line 82</Data>
</EventData>
</Event>
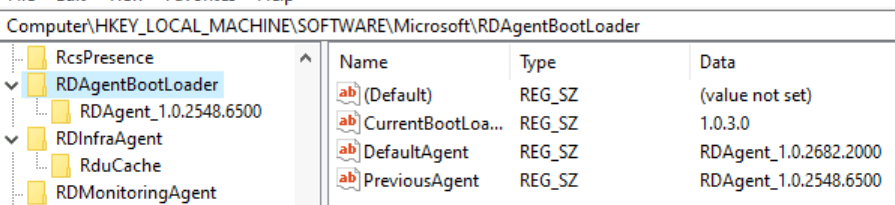
The first thing that stood out to me was “Unable to retrieve DefaultAgent from registry“, and after a quick search to see where that registry key was, I found it at: \HKLM\SOFTWARE\Microsoft\RDAgentBootLoader
Looking at my settings, I saw the “DefaultAgent” is pointing to an entry version that is not in my registry:
Hmm…. if it’s pointing to a version that there’s no key, let me check if the binaries are there on the machine. Yes, they were! So let me try creating the missing key by checking to see what was in the existing key:
Ok, let’s create the missing key in the same syntax as the existing one:
After a restart, the session hosts are now Available and stable!
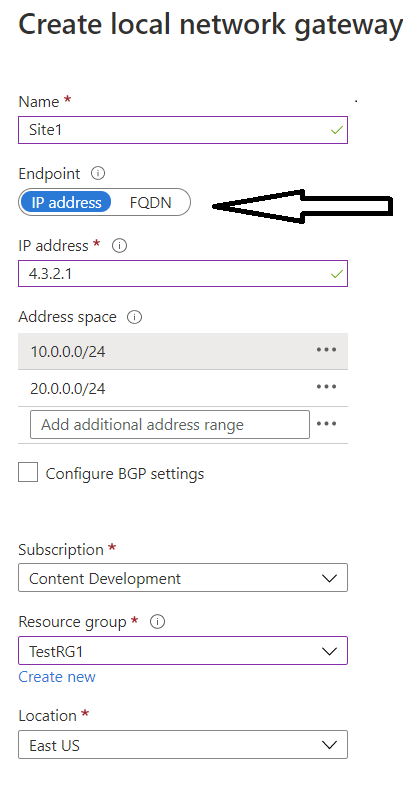
As of November 20, 2020, Azure now supports FQDN configurations for it’s VPN connections!
This is perfect for customer branches or locations without static public IP addresses (private homes behind a cable modem, etc.) to connect to the Azure VPN gateways. Dynamic DNS services can be leveraged to use the Fully Qualified Domain Name (FQDN) instead of IP addresses!
Lucia Stanham wrote an amazing article at Azure blog on some observations I had before I was able to write my own, so instead of rehashing the same thing, I’m posting the article instead:
A need for hybrid and multicloud strategies for financial services
The financial services industry is a dynamic space that is constantly testing and pushing novel use cases of information technology. Many of its members must balance immense demands—from the pressures to unlock continuous innovation in a landscape with cloud-native entrants, to responding to unexpected surges in demand and extend services to new regions—all while managing risk and combatting financial crime.
At the same time, financial regulations are also constantly evolving. In the face of the current pandemic, we (at Microsoft) have seen our customers accelerate in their adoption of new technologies, including public cloud services, to keep up with evolving regulations and industry demands. Hand in hand with growing cloud adoption, we’ve also seen growing regulatory concerns over concentration risk (check out our recent whitepaper on this), which have resulted in new recommendations for customers to increase their overall operational resiliency, address vendor lock-in risks and require effective exit plans.
Further complicating matters, many financial services firms oversee portfolios of services that include legacy apps that have been in use for many years. These apps often cannot support the implementation newer capabilities that can accommodate mobile application support, business intelligence, and other new service capabilities, and suffer from shortcomings that adversely affect their resiliency, such as having outdated and manual processes for governance, updates, and security processes. These legacy applications also have high vendor lock-in because they lack modern interoperability and portability. Furthermore, the blunt force approach of leveraging legacy technology as a means for protecting against financial crime is an unsustainable strategy with diminishing returns—with big banks spending over $1 billion per year maintaining legacy infrastructure and seeing a rise in false positive rates as financial crime evolves in sophistication.
As a means to address the demands of modernization, competition, and compliance, financial services organizations have turned to public cloud, hybrid cloud and multi-cloud strategies. A hybrid model enables existing applications—which originally exist on-premises—to be extended by connecting to the public cloud. This infrastructure framework unleashes the benefits of the public cloud—such as scale, speed, and elastic compute, without requiring organizations to rearchitect entire applications. This approach provides organizations the flexibility to decide what parts of an application should reside in an existing datacenter versus in the public cloud, as such providing them with a consistent and flexible approach to developing a modernization strategy.
Additional benefits of successful hybrid cloud strategies include:
A unified, consistent approach for infrastructure management: Consistently manage, secure and govern IT resources across on-premises, multicloud and the edge, delivering a consistent experience across locations.
Extending geographic reach and openings new markets: Meet the growing global demand and extend into new markets by extending the capabilities of datacenters to new locations – while also meeting data localization requirements from local markets
Managing security and increasing regulatory compliance: Hybrid and multicloud are great alternatives for strictly on-premises strategies due to cloud benefits around service security, availability, resiliency, data protection and data portability. These strategies are often referenced as a preferred way of reducing risk and addressing regulatory compliance challenges.
Increasing Elasticity: Customers can respond with agility to surges in demand or transaction by provisioning and de-provisioning capacity as needed. A hybrid strategy allows organizations to seamlessly scale their capacity beyond their datacenter during high-compute scenarios, such as risk computations and complex risk modeling, without over exhausting servers or slowing down customer interactions.
Reducing CapEx Expenses: The cloud makes the need for such a large capital outlay for managing on-premises infrastructure unnecessary. Through the benefits of elastic capacity in hybrid scenarios, companies can avoid the costs of unused digital capacity, paying only for the resources that are consumed.
Accelerate time to market: A hybrid strategy provides a bridge that connects on-premises data to new cloud-based capabilities across AI and advanced analytics, allowing customers to modernize their services and unlock innovation. With virtualized environments, they can accelerate testing and evaluations cycles and enable deployment seamlessly across different locations.
A multicloud strategy enables customers to leverage services that span different cloud platforms, enabling them to select the services best suited to the workloads or apps they are managing.
Commonly cited benefits of a multicloud strategy include:
Flexibility: Customers wish to have the flexibility to optimize their architectures leveraging the cloud services best suited to their specific needs, including the flexibility to select services based on features or costs
Avoiding vendor lock-in: A common requirement customers often state, customers often seek design multi-cloud deployments to achieve short term flexibility and long-term agility by designing systems across multiple clouds.
Microsoft hybrid and multicloud edge for financial services organizations
Azure hybrid capabilities uniquely address some of the main barriers customers face around hybrid and multicloud strategies. Managing multiple environments is an endeavor that introduces inherent complexity and risk for firms, faced with an expanding data estate that spans diverse on-premises, public cloud(s), and edge environments. Optimizing for productivity without sacrificing security and compliance can be daunting. Azure provides a seamless environment for developing, deploying and managing data and applications across all distributed locations.
For one, Azure uniquely supports the full range of hybrid capabilities across DevOps, Identity, Security, Management, and Data. Given that customer IT estates involve much more than containers, many of our cloud benefits are also available to server-based workloads. Azure enables customers to manage both Windows and Linux servers across their data estate and customers can also manage access and user authentication with hybrid identity services. The Azure Stack portfolio extends Azure services and capabilities to your environment of choice—from the datacenter to edge locations and remote offices and disconnected environments. Customers can run machine learning models on the edge, in order to get quick results before data is sent to the cloud. Furthermore, with capabilities such a Azure Stack Hub, our portfolio enables organizations to operate in offline environments that block data from being sent to the public cloud, especially if required for regulatory compliance.
Second, Azure simplifies the experience of managing a complex data estate by providing a unified, consistent approach for managing and monitoring their hybrid or multicloud environments. With capabilities such as Azure Arc, can manage their data estate with a single management plane—including the capability to monitor non-Microsoft clouds. Customers can also take a similarly simplified approach to managing security across their estate with services such as Azure Sentinel, which provides a consistent threat detection and security analytics view across on-premises, cloud and edge devices. In combination with services such as Azure Security Center, Azure policy, and Azure advisor, customers can also design, deploy, and oversee security and compliance of their deployments across their hybrid and multicloud environments.
Azure leadership in hybrid and multicloud offerings is also rooted in our extensive collaborations with hardware partners (OEMs), which whom we have partnered and co-engineered solutions to deliver a well-defined variety of supporting devices. Partner solutions have been designed with the aim in mind to increase resiliency and expand the reach of virtual data centers. With the new rugged series of Azure Stack Edge for instance, we provide cloud capabilities in the harshest environment conditions supporting scenarios such as tactical edge, humanitarian and emergency response efforts.
The Azure commitment to financial services customers stems from Microsoft industry-leading work with regulators around the world. Our customers require their cloud partners to support transparency, regulatory right to audit, and self-reporting. To enable this, we have a dedicated and comprehensive FSI compliance program available to customers and help customers manage their compliance by enabling choices around data location, transparency and notification of subcontractors, providing commitments on exit planning (see our recent blog here), as well as tools to aid in risk assessments.
Customer spotlights
We’ve seen many of our financial services customers begin to realize the benefits of hybrid and multicloud strategies already. In a recent Total Economic Impact study commissioned with Forrester on the impact of shifting from on-premises to Azure IaaS (including to hybrid environments), over a three year period, organizations avoided 90 percent of on-premises infrastructure costs (valued at over $7 million), as well as associated employee costs. Organizations were able to reallocate their IT staff to higher level business initiatives, including ventures of expansion into new markets, which resulted in altogether new streams of income for the companies.
One example of a company that took a hybrid approach was Banco de Crédito e Inversiones (BCI). Their portfolio supported 20 million transactions a month and required a hybrid approach in order to keep apps and resources on-premises for regulatory and performance reasons. With Azure Stack Hub, they were able to improve the performance and reliability of their systems, and even rolled out new products quickly. They were able to switch from outsourced IT management to in-house management.
“We’ve found the whole Azure platform to be very reliable and stable, and it gets better with each release. In fact, we have statistics showing that when we enabled Azure Stack Hub, customer satisfaction went up. It’s very clear. We’re delivering a better experience for our customers through the reliability and performance of Azure Stack Hub and the new functionality our team is building on top of it.”—German Matosas, Head of Architecture and Cloud Platform, BCI
Another example is Volkswagen Financial Services, a branch of VW that manages approximately 80 web apps across ten countries—a complex IT estate by any measure. They needed to modernize their apps and development approach and leveraged Azure Stack Hub to bring cloud speed and scale to their DevOps practices. This strategy also allowed them to maintain components of their highly customized apps on-premises (such as core databases and SAP systems), due to privacy and compliance requirements. This also enabled them to add new services without needing to rework their existing applications.
What about full or single cloud?
While the focus of this blogpost has been hybrid and multicloud strategies, it is also worth briefly touching on the value of partnering with a single cloud provider to provide end-to-end solutions. This is referred to as a “full cloud” or “single cloud” strategy and serves the long-term objective of shutting down all on-premises data centers and moving all workloads to a single cloud provider. This strategy also has its merits and in fact may offer benefits over both hybrid and multicloud solutions, such as offering simplified management, less complexity, and lower total cost of ownership (TCO). Partnering with a highly resilient CSP, such as Microsoft, for a full cloud strategy, has been the solution of choice for several financial institutions. The unique benefits of a full cloud strategy need to be weighed against potential downsides, but in principle, this approach is allowed by regulators in most global jurisdictions.
Deciding on a hybrid or multicloud strategy
Many organizations commence their journey from a fully on-premises baseline. We’ve seen that as they start to consume public cloud services, questions arise around what the most appropriate deployment strategy could be—whether they should take a full cloud, hybrid cloud, or multicloud approach.
If you respond positively to one or more of the questions below you are likely in a good position for using hybrid or multicloud strategies:
Does your organization’s digital strategy enable your organization to easily adopt new and emerging technologies and deploy them to on-premises or legacy apps?
Does your organization have a digital strategy that welcomes innovation but is not ready to fully commit to a public cloud?
Do you find it challenging to meet capacity demands in your IT infrastructure and meet unexpected surges in demand or maintain performance levels?
Does your IT department struggle to manage different technologies from different providers and keep oversight across multiple environments?
Does your organization face pressure from regulators or risk departments to maintain certain processes on-premise, or within specific geographic regions (data residency)?
Is your organization considering expanding into new geographies or new markets?
I recently had to add a bunch of users to an AzureAD group where the UserPrincipalName was different than the user account, thus causing all sorts of failures when adding it in the PowerShell CLI as well as the bulk add from the Azure web portal.
What I wanted to point out is that you can use any of the ExtensionProperties that the user account contains.
For instance, here’s the script I threw together to add users to a group based on their “mail” property:
$imp1 = Import-Csv C:\users\luceds\desktop\exp1.csv
ForEach ($line in $imp1)
{
$mem1 = Get-AzureADUser -Filter "mail eq '$($line.UPN)'"
$mem1 # drop the name on the screen to check for errors
Add-AzureADGroupMember -ObjectId 0c3ac25f-449b-4057-bd16-826269exxxxx -RefObjectId $mem1.ObjectId
}
The “queryingcollections” section in the oData document page show the syntax that’s possible for the -Filter parameter
What are you getting by moving to “Cloud services” vs “on-Premise”? Make sure expectations are set with Executive Management as to what they’re gaining, but also losing.
Over the past 30 years I’ve seen a push from Cloud to On-Prem to Cloud and back untold amounts of times. Yes, those terms were not specifically used, technologies evolve, but the pendulum swings back and forth for many reasons. Right now there’s a massive push for “Cloud being the holy grail”, business owners are embarrassed if they’re not there, strongly feel they’re missing out, and doing it wrong if not.
Over the years, the biggest reason I’ve seen it swing back to “On-Prem”, staying insourced, or any other naming convention that’s used is due to support, speed, service uptime, and reliability!
We all know that “Cloud” is supposed to be so much cheaper when you factor in support costs vs paying for full inhouse salaries, however, setting expectations is quite important. The saying “you get what you pay for” absolutely applies here.
Let’s take one system as an example: Microsoft Exchange is a complex system, dependent on a very wide range of infrastructure. Yes, to support that service in one’s company an administrator must be well versed in a large variety of systems and technologies, and as a result, that person will be expensive to have on staff.
If you have access to such a resource (on staff, on a retainer, etc.), system availability is high, with rapid fault resolution when events occur.
Amongst many other things, I personally concurrently manage the Msft Exchange environments for 6 different companies, 3 of them over 10 years now. How much of my time does that take up? An average of 60 min a week for all of them combined! (wait, wha….?? I thought environments like that are a beast to manage? – Well, not when they’re configured correctly, and maintained) – These are highly available, fully redundant systems mind you. In those 10+ years, not once has any company been out of email service for over an hour due to systems under my support. (Once an ISP was down for several hours on the US East coast, and that caused a long lasting service outage for one of the companies) – Have there been issues? Absolutely, but the resolution has typically been under 30 min once contacted, with full system availability nearly constant during business hours.
Let’s look at Microsoft 365 Cloud email service in comparison:
I was recently hired by an very large company to migrate their on-premise Exchange service to 365, and in just the first 6 months of doing so, email outages for them have already been:
Over 4 hours
Over an entire day
Half a day
Several 1 hour outages
If this were systems I was in charge of managing, with very good reasoning, I would be out of a job! Everyone knows that “Cloud” is the best though, so we just work around it, and chalk it up to “eh, it’s what management wants….”
Let’s talk about 365 support for a bit:
When you call do in for support, mean time for incident resolution spans between several hours, to several days! Unless you spend a very good amount of money on fast support, the only available options are submitting a support request on the portal and wait for someone to call you back (typically in a couple of hours). Hopefully, you’re available to work on the request, but the vast majority of time, you’re not, so realistically, that support ticket can span several days! – My experience, close to 90% of the time I get a call back when I’m out of any ability to work on the issue, it’s madding! – Yes, those support requests are not for an entire system being down (those, you have zero visibility into “why, when will it come back up, etc….” best of luck…), I’m talking about any wide ranging amount of reasons you have to call in support due to the fact you don’t control or have access to the full infrastructure.
There are loads of reasons to move your infrastructure to the “cloud”, but if you do, make sure expectations are set with Executive Management as to what they’re gaining, but also losing by doing so. In my experience, service availability, and performance is worse, with possible feature set lost for the (uh, cloud is usually higher) cost of licensing and supporting on-premise solutions.
Here are some links during for very large Office 365 outages during September/October, there have been other large ones earlier that a simple web search can bring up:
Analog trunks and devices are less and less of a factor in many of the projects that I work on. Areas where I still see analog are branch office trunks, faxes, door buzzers/enterphones, paging systems, and ring-down phones that you might see in a parking lot to contact security or a cab company.
To integrate analog trunks or devices with SfB or Teams, you connect them to a gateway. The gateway can come with two types of ports: FXO, and FXS. FXO is an abbreviation for Foreign eXchange Office, and FXS for Foreign eXchange Subscriber.
So, clear as mud and we’re done here, right? If you’re an old school telecom guy, you know there’s a lot of complexity hidden behind that simple jack in the wall. The good news is for nearly all SfB use cases we can boil things down so they’re very simple.
FXO is a port that you plug a telco trunk line into. FXS is a port that you plug your phone or other device into. Mostly. Confusion pops into the picture when you have paging systems or enterphones, which may oddly use the opposite interface than you’re expecting, or give you the option for both.
You can think of FXO and FXS as North and South on a magnet, or male and female, or whatever pairing you’d like. A FXO device plugs into an FXS device, and all is well, like this:
Your phone, which has an FXO jack on it, plugs into the wall, which is an FXS interface.
Your phone, which has an FXO jack on it, plugs into an Analog Gateway such as the AudioCodes MP-118 gateway FXS port, or an FXO/FXS card in a Sangoma for instance.
The AudioCodes MP-114 gateway FXO jack plugs into the wall, which is an FXS interface.
An AudioCodes MP-114 gateway. From the left are power, Ethernet, RS-232 serial console, two FXS ports and two FXO ports.
Great, so why then would a paging system offer both FXO and FXS interfaces? The answer is that there are two different use cases for the paging system.
One use case is a standalone, where a phone plugs directly into the paging system. You pick up the phone, maybe enter some digits to indicate what zone to page, and you talk away. The paging system is acting as a PBX in this scenario.
The second use case is PBX integrated, where the paging system acts as a phone. You dial the extension for the paging system, it rings and then answers, you maybe enter some digits to indicate what zone to page, and you talk away.
These two use cases also apply to things like enterphones or gate/door buzzers. You can have a phone plugged directly into the enterphone, or you have have the enterphone act as an extension on your PBX.
The standalone option is simple, but restricts you to interacting via a single phone. The PBX integrated option is more complex, but allows you to interact via any phone on the PBX.
Caution: “Interact via any phone on the PBX” in the SfB world means that in a global deployment, you could have a prankster user in New York telling jokes over a paging system in Paris. Configure your dial plans appropriately if your paging system doesn’t offer PIN functionality
If you have a choice between using an FXO port or FXS port on a gateway to integrate with an analog device that offers both, I recommend you pick the FXO port. This has the device act as a PBX, which means that there is no ringing when you call it, and call setup is faster. Disconnects are usually quicker too, which is important if the paging system or enterphone is used a lot.
When you configure the device to plug into an FXO port on the gateway, set the gateway to route calls to that number out via the FXO port you’ve connected it to. If the device will be sending calls to the gateway, set the gateway to
You’ll need to use an FXS port on your device to connect to the gateway’s FXO port. If your device has one port that’s switchable between FXO and FXS, read the manual carefully – I’ve seen some that aren’t clear whether they mean FXO mode is “setting this device to FXO” or “setting this device to talk to FXO”. If it’s really unclear, plug a boring analog phone in. If the line is dead, the device is set to act as an FXS device and the port is configured as an FXO interface.
I recently came across a scenario, where an Exchange environment that had been configured in a Best Practice state had failed over to the DR site due to an extended network outage at the primary production site, and was unable to re-seed back and fail back over.
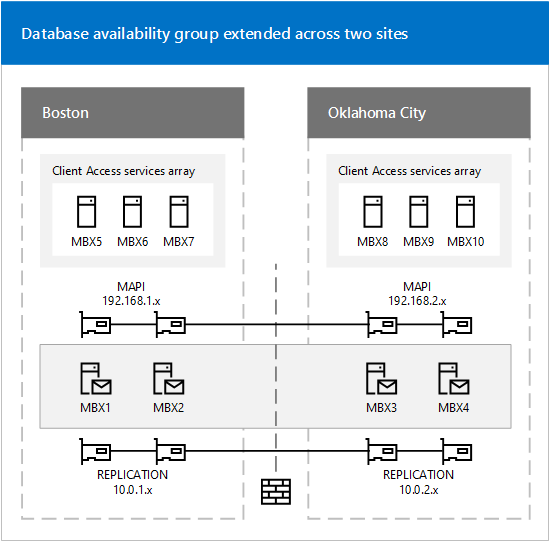
The environment was configured very similar as described in the Deploy HA documentation by Microsoft, and had it’s DAG configured across two sites:
Stock example showing DR site relationship
Instead of the “Replication” network that is shown in the above graphic, the primary site had a secondary network (subnet 192.168.100.x) where DPM backup services ran on, the DR site did not include a secondary network.
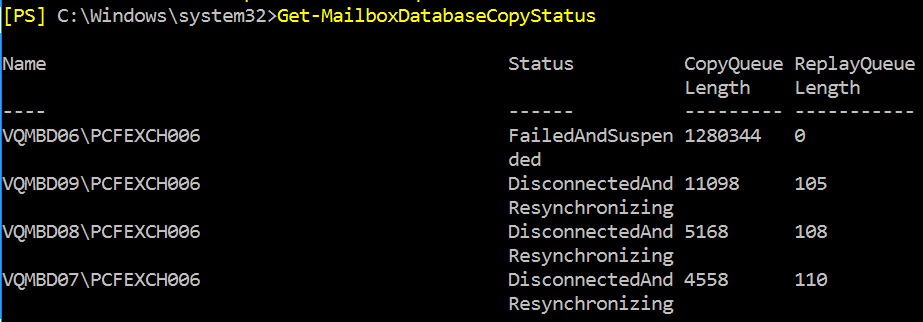
Although the Exchange databases were mounted and running on the DR server infrastructure, the replication state was in a failed state at the primary site. Running a Get-MailboxDatabaseCopyStatus command showed all databases in a status of DisconnectedAndResynchronizing
DisconnectedAndResynchronizing state
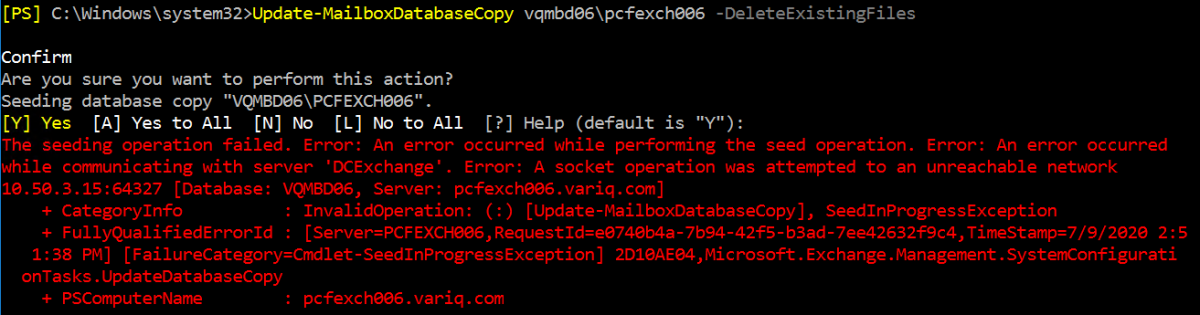
All steps attempted to try to re-establish synchronization of the databases failed with various different error messages, even deleting the existing database files and trying to re-seed the databases failed, with most messages pointing to network connectivity issues.
Update-MailboxDatabaseCopy vqmbd06\pcfexch006 -DeleteExistingFiles
Confirm
Are you sure you want to perform this action?
Seeding database copy "VQMBD06\PCFEXCH006".
[Y] Yes [A] Yes to All [N] No [L] No to All [?] Help (default is "Y"):
The seeding operation failed. Error: An error occurred while performing the seed operation. Error: An error occurred
while communicating with server 'DCExchange'. Error: A socket operation was attempted to an unreachable network
10.50.3.15:64327 [Database: VQMBD06, Server: pcfexch006.xxxxx.com]
+ CategoryInfo : InvalidOperation: (:) [Update-MailboxDatabaseCopy], SeedInProgressException
+ FullyQualifiedErrorId : [Server=PCFEXCH006,RequestId=e0740b4a-7b94-42f5-b3ad-7ee42632f9c4]
[FailureCategory=Cmdlet-SeedInProgressException] 2D10AE04,Microsoft.Exchange.Management.SystemConfigurationTasks.UpdateDatabaseCopy
+ PSComputerName : pcfexch006.xxxxx.com
Looking carefully at the error message, the error says: A socket operation was attempted to an unreachable network 10.50.3.15:64327
Very strange, as when a network test was run, no errors occurred with connecting to that IP and TCP port.
When the test command Test-ReplicationHealth was run, the ClusterNetwork state was in a failed state:
PCFEXCH006 ClusterNetwork *FAILED* On server 'PCFEXCH006' there is more than one network interface
configured for registration in DNS. Only the interface used for
the MAPI network should be configured for DNS registration.
Network 'MapiDagNetwork' has more than one network interface for
server 'pcfexch006'. Correct the physical network configuration
so that each Mailbox server has exactly one network interface
for each subnet you intend to use. Then use the
Set-DatabaseAvailabilityGroup cmdlet with the -DiscoverNetworks
parameters to reconfigure the database availability group
networks.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.3.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '192.168.100.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
Subnet '10.50.2.0/24' on network 'MapiDagNetwork' is not Up.
Current state is 'Misconfigured'.
The Failover Cluster Manager was checked, but no errors were found, and the networks in question were “Up”, and in green status.
Looking further at the output of the Test-ReplicationHealth shows that the current state is “Misconfigured”, so let’s see how that replication traffic is configured. The following shows the output of Get-DatabaseAvailabilityGroupNetwork
Running Get-DatabaseAvailabilityGroupNetwork | fl showed no visible change, but the Site-to-Site tunnel showed a massive uptick in usage, so I ran the Get-MailboxDatabaseCopyStatus command, and it showed all databases that were in a status of DisconnectedAndResynchronizing synchronizing! I retried the reseed process, and it worked!
I’m not sure why the Set-DatabaseAvailabilityGroupNetwork command showed no visible changes, but it’s obvious the changes did occur, that the replication was disabled over the BackupNet (192.168.100.x) and forced over the correct network.
I’ve been pretty quiet as of late, primarily due a major push this past year in achieving the premier Azure infrastructure certification from Microsoft.
After configuring Audiocodes’ VM based SBC in a single NIC state, a need come up where a WAN interface needed to be brought online. When attempting to set an IP to the interface group the following error was displayed:
nwDevTable_CrossValidateRow: Validation failed, the ethernet group (index 1) already contains the OSN interface. No other device can be configured on this group. MATRIX DeviceTable: Unable to Activate Line(1) since it is invalid
As we can see, the Ethernet Device Status shows InternalIF OSN is the only other available device.
IP Interface Status doesn’t show much help either:
An idea attempted was exporting the configuration ini file, adding the configuration entries for the second NIC, applying the changed configuration file and restarting appears to bring it up, but it still had a red state of down/unknown. (the WAN_DEV Ethernet Device was created in the config file)
The following steps were taken to get the Audiocodes VM to work:
Delete the logical Virtual Machine network interface
Restart the VM
Add a new NIC to the VM
Restart the VM
Once those steps were taken, the interface came up, and the IP was active!