The case of the dropped call at the 10 min mark:
We have a SIP trunk provider that due to their implementation of RFC requirements, send down a Re-Invite packet at the 10 minute mark. If you’re just running a single server, there’s no issue, as the FE that gets the packet sends back an ACK packet saying “got it”, and communication continues. When you have multiple servers, it can be an issue, as in this provider’s case, they only send that Re-Invite packet to the first registered IP, and if the outgoing call originates from one of the other servers, they never get that Re-Invite packet, can’t send back an ACK, and the call gets dropped due to timeout.
To mitigate the above mentioned case, an SBC was put in the middle so that the trunk would only have one IP to communicate to, all was fine and dandy, but due to the nature of things changing in an IT environment, a new random call drop issue came up. (Ugh!)
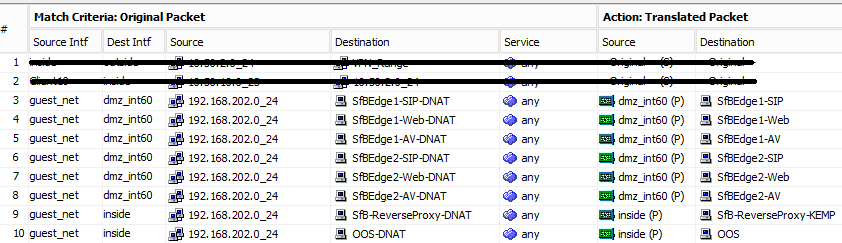
To see what was going on, client and server Skype for Business logs were looked at for the time the drop occurred, they showed a standard “BYE” happening, not an error, so onto looking at the next step, infrastructure.
In order to give some concept of the environment, here is a basic diagram of what it looks like:
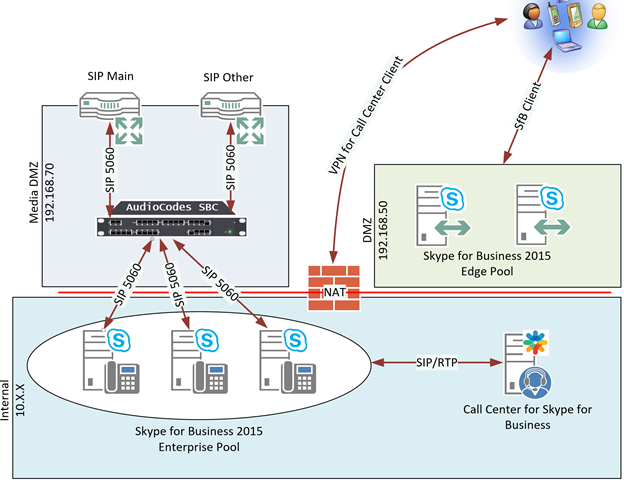
Note that there is NAT’ing going on between the networks, the SBC was configured with the IP 192.168.70.44 (in the syslog figures, it shows up as “Device”) the internal FE servers had NAT addresses of 192.168.70.20, 21, and 22. We’ll get back to that in a bit.
Syslog was enabled on the SBC, perused through those, and this is what I found:
In the process to narrow down what was going on, we found that in the majority of complaints, the calls were getting dropped at the 10 min mark, and since the Re-Invite gets sent at that time, the SIP provider was in the crosshairs, and that was our main focus. After much going back and forth with them, going back and forth with the SBC vender, tearing up the servers, time to start fresh, and look deeper.
In looking at the logs, there are some calls that the re-invites are handled correctly: Here are two long ones, one lasting 13 min, the other almost 30, both with Re-Invite packets, (the second one with three).

Eventually I found some calls that failed, here’s an example of one that wasn’t handled correctly:
Notice the call is only 2 seconds long, but still dropped!

Here’s a screenshot of the Re-Invite hangup problem:
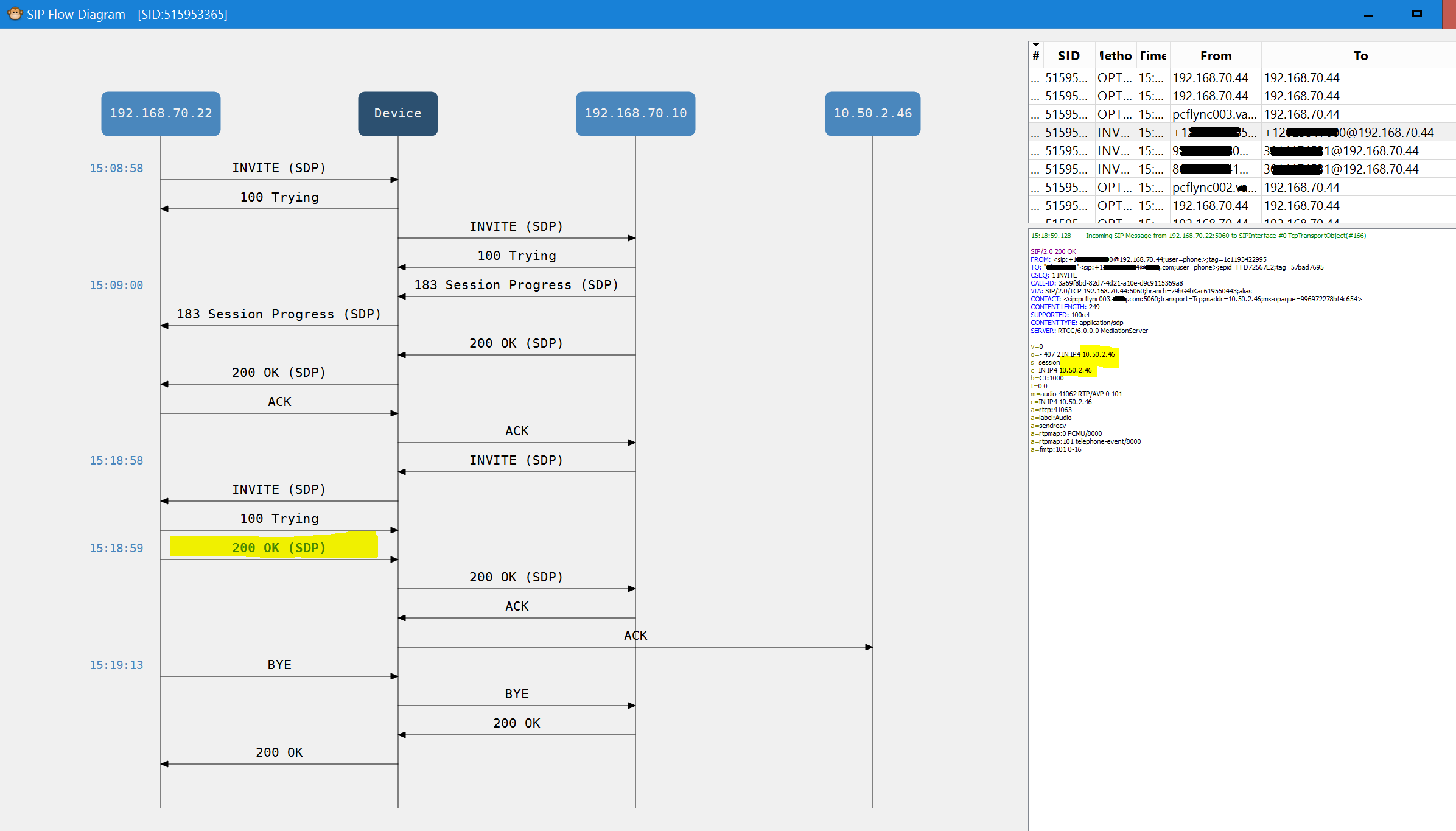
Here we see the Re-Invite packet coming down at exactly 10 min after the call started (15:08:58), when the internal server answers that with its SDP packet, the address doesn’t get NAT’d, the SBC then tries to send it to the Internal IP, that communication doesn’t occur, and after a period of no communication (14 sec in this instance), the server assumes the call has ended, has the BYE packet sent to drop the call.
So, from looking at all the calls with the syslog viewer, I saw sporadically there were calls failing, and others succeeding, there didn’t seem to be any rhyme or reason to it, except for the failure was always right after an SDP packet coming from the inside server.
This now had me looking at ALG, which in this case, is controlled by the firewall. What is ALG? To put it simply, it is NAT for SIP SDP packets. What is SDP? While SIP deals with creating, modifying, and closing down sessions, SDP deals with the media within those sessions. and what we’re specifically interested in this scenario, is the IP addresses the two endpoints should talk over. Since one of the endpoints is behind a NAT’d device, ALG is the mechanism that changes the data in these packets to have IPs the two devices can talk to!
Thankfully, this firewall makes it easy to capture inbound packets and outbound packets separately in the same session, producing two separate pcap files which can be compared to side by side! Let’s look at packet #24 of a call that does work:
Here is the inbound packet, notice the O and C attributes have the internal IP, as it’s originating from inside the network:

Once it goes through the firewall, here is the outbound version of that exact same capture, you can see the O and C attributes have been changed to the NAT IP by ALG:

Here’s an example of a complete failure capture. Note, this was from an “updated” firmware version of the firewall that completely blew up NAT, so the capture was easy to catch, but the concept is the same which is occurring with the sporadic failures above:
Here is the inbound packet #4, notice the O and C attributes have the internal IP, as it’s originating from inside the network:
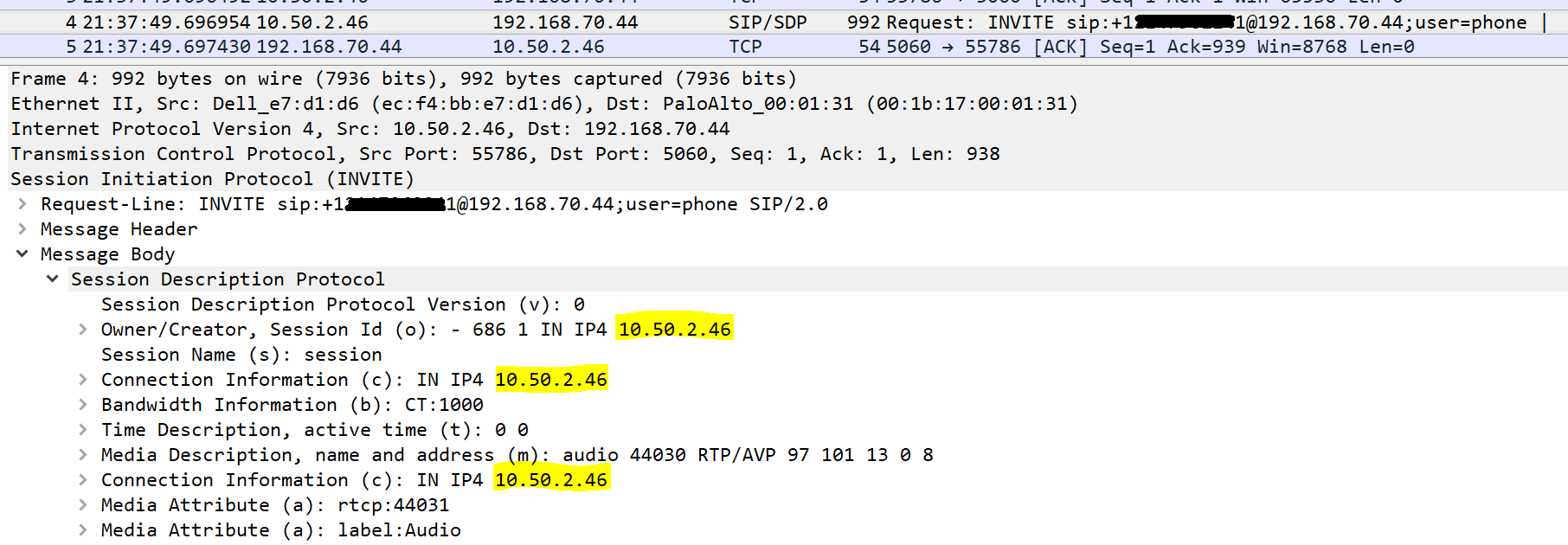
Once it goes through the firewall, here is the outbound version of that packet #4, you can see the O and C attributes have NOT been changed to the NAT IP by ALG:

Let’s take a look at that syslog trace again:
We can see the original invite comes from the Skype FE server (10.50.2.46, which is NAT’d to 192.168.70.22), communication goes to the SBC, and then gets sent up to the SIP provider’s CPE SIP router. Everything works great until one of the SDP packets does not get translated through ALG correctly, when that happens, the SBC does not know where to send the packet, it gets sent to the “Internal” IP, subsequently goes nowhere, and 14 seconds later, the stream is disconnected with a “BYE” packet due to inactivity.
Why did this problem arise out of the blue? I’m guessing there have been some good firewall firmware versions that have not caused any issues, so there has been some periods of tranquility, with other firmware versions that have “sometimes” caused this issue. The current firewall version installed is 7.1.5. I’ve tried 7.1.8, 8.0, and 8.0.2, they are progressively worse (with 8.0 and higher not working at all), so I went back down to 7.1.5, and am awaiting resolution from the manufacturer.
Another solution is to change the architecture of the network boundaries affected to be Routed instead of NAT’d, that way ALG does not come into the picture. That might not be a feasible solution due to your security or infrastructure constraints, but has solved the issue (temporarily) in this case. It is not a permanent fix, as any SIP conversations going over NAT will continue to be an issue until the vendor resolves it in their firmware.